
들어가며
세션에 대해 조금씩 이해를 하고 있지만, 세션을 어떻게 활용해야 잘 활용할 수 있는 것인지에 대해 정리해보고 싶었습니다. 세션을 쓸 때 어떤 것들을 고려해야 하는지에 대해 더 늦기 전에, 기초를 쌓고 싶어서 개념을 정리해보고자 합니다. 무지를 반성하는 마음으로 이 글을 적습니다.
세션 스토리지 설정
2편에서는 다중 서버 환경에서 세션 데이터 불일치 문제를 어떻게 해결할 수 있는지에 대해 알아봤습니다. 여기서 별도의 세션 스토리지를 구성해서 세션 데이터 불일치 문제를 해결하는 방법까지 알아봤는데, 여기서 생각해볼 문제가 있습니다. 웹 서비스의 특성상 대부분의 요청은 인가된 사용자가 보내는 요청인지 확인하는 절차가 선행되어야 합니다. 이때 요청마다 사용자가 인가된 사용자인지 확인하기 위해 매번 세션 스토리지를 확인해야 합니다. 이러한 특성을 고려한다면 세션 스토리지를 선정할 때, 성능에 영향이 미치지 않도록 빠르게 데이터를 찾아야 하는데, 이때 어떤 데이터베이스가 세션 스토리지에 적합한지 지금부터 알아보겠습니다.
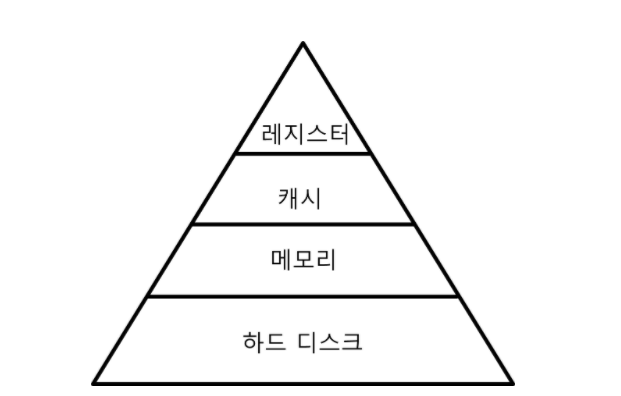
Disk based DB와 In-Memory DB
데이터베이스는 데이터가 어느 곳에 저장이 되는가를 기준으로 디스크 기반의 데이터베이스와 In-Memory 데이터베이스로 분류됩니다. 디스크 기반의 데이터베이스는 데이터를 Disk에 저장하여 관리하며, In-Memory 데이터베이스는 메모리에 데이터를 저장하고 관리하는 데이터베이스를 말합니다. 그럼 먼저 디스크 기반의 데이터베이스에 대해 알아보겠습니다.
Disk based DB
디스크 기반의 데이터베이스는 디스크에 저장된 데이터를 메모리의 임시 저장소(버퍼) 공간에 페이지(블록) 단위로 읽어옵니다. 그래서 만약 디스크 기반의 데이터베이스가 데이터를 조회한다면 버퍼 공간에서 먼저 데이터를 찾고, 데이터가 존재하지 않을 경우 디스크에 있는 페이지(블록)을 다시 읽어오는 방식입니다. 이는 메모리 I/O 작업이 디스크I/O 작업에 비해 10,000배 이상 빠른 장점을 잘 살린 방법입니다. 하지만 디스크에서 데이터를 찾아 페이지 단위로 버퍼로 전송하는 시간이 발생하기 때문에 여러 I/O 작업 처리에 있어서 병목 현상이 발생하게 됩니다.
이러한 이유로 세션이 존재하는지 확인하는 작업을 여러번 반복해야 하는 서비스에서 세션 스토리지로 Disk based DB를 사용하는것은 성능적인 측면에서 올바른 선택이 아니라고 생각합니다. 그렇다면 In-Memory DB는 어떨까요?

In-Memory 데이터베이스를 사용해보자!
In-Memory DB는 애초에 모든 데이터를 메모리에 저장하기 때문에 Disk I/O 작업이 발생할 일이 없습니다. 따라서 디스크 기반의 데이터베이스에서 발생하는 병목 현상을 피할 수 있습니다. 그렇다고 Disk based DB보다 In-Memory DB가 무조건 더 좋다고 말할 수 없습니다. 각각의 방식은 사용하는 환경과 상황에 따라 장단점이 있습니다. 그렇다면 In-Memory DB의 단점은 무엇일까요?
In-Memory DB는 주 저장소로 휘발성 메모리인 RAM을 사용하기 때문에 기본적으로 영속성을 보장하지 않습니다. 만약 예상치 못한 에러나 오류로 인해 프로세스가 종료된다면 데이터가 모두 유실될 수도 있습니다. 그렇다면, 영속성을 보장하지 못한다는 특징이 있을 때, In-Memory DB를 session을 저장하는 저장소로 사용하는 것이 적합할까요?
세션은 HTTP의 비연결 지향과 상태없음(stateless)과 같은 특성을 보완하기 위해 사용하는 것입니다. 세션에는 주로 로그인한 사용자의 정보를 저장하는데, 이 정보는 영원히 저장되어야 하는 정보가 아닙니다. 사용자가 로그아웃을 하거나 개발자가 설정해놓은 세션의 timeout에 따라서 세션이 제거됩니다. 세션에 저장되는 데이터의 위와 같은 특성 덕분에 데이터 유실로 인해 발생하는 피해가 다른 데이터에 비해 적습니다. 극단적인 예로 세션 저장소의 데이터가 유실된다면 사용자는 재 로그인만 진행하면 됩니다. 따라서 세션 스토리지로 In-memory DB의 사용이 적절하다고 생각합니다.

또한 몇몇 In-Memory DB는 세션 스토리지 서버에 문제가 생겨서 데이터가 유실되는 것을 방지하기 위해 Replication이라는 기능을 통해 failover를 지원합니다. 동일한 데이터를 또 다른 세션 스토리지에 복사하는 [마스터-슬레이브] 복제 방법을 사용하거나 'Consistent Hashing' 알고리즘을 사용하여 가용성을 보장하기도 합니다.
그렇다면, In-Memory DB에서도 어떤 것을 활용해서 세션 스토리지를 구성할 수 있을까요? 이에 대해서는 다음 포스팅에서 알아보도록 하겠습니다!

마치며
공부를 하며 그동안 아주 기초적인 것들을 제대로 공부하지 않았다는 것을 깨닫습니다. 좋은 기술을 배우는 것도 좋지만, 기술의 기반이 되는 기초적인 지식을 먼저 쌓는 것이 중요하다는 것을 다시금 깨달았습니다. 기초가 튼튼한 개발자가 되고 싶습니다.
출처
다중 서버 환경에서 Session은 어떻게 공유하고 관리할까? - 3편 (Disk based database vs In-Memory database)
개요 지난 시간 다중 서버 환경에서 별도의 세션 스토리지를 구성하여 정합성 이슈를 해결하기로 하였습니다. 여기서 생각해볼 문제가 있습니다. 웹 서비스의 특성상 대부분의 요청은 인가된
hyuntaeknote.tistory.com
Session storage로 적합한 데이터 베이스는 무엇일까? (Redis vs Memcached)
Session storage로 적합한 데이터 베이스는 무엇일까? (Redis vs memcached) 지난시간에 포스팅했던 서버가 두 개 이상일 경우 발생하는 세션 불일치 문제 해결하기에서 별도의 세션 스토리지를 구성하여
1-7171771.tistory.com
'Web' 카테고리의 다른 글
| [Web] JWT 토큰을 알아보자 (0) | 2022.01.14 |
|---|---|
| [Web] 다중 서버에서 세션을 관리해보자 - 4 (feat Redis, Memcached) (0) | 2022.01.11 |
| [Web] 다중 서버에서 세션을 관리해보자 - 2 (feat 세션 불일치) (0) | 2022.01.05 |
| [Web] 다중 서버에서 세션을 관리해보자 - 1 (feat Scale-up, Scale-out) (0) | 2021.12.29 |
| [Web] 세션을 알아보자 (0) | 2021.12.23 |



