
들어가며
사이드 프로젝트에서 푸시 알림을 활용한 서비스를 개발하고 있습니다. 그 과정에서 생각하고 배웠던 점들을 하나씩 작성하고자 합니다. 먼저 푸시 알림 서비스를 구축하려면, Queue를 활용해야겠다고 생각했습니다. FCM을 활용하다 보면, 하나의 푸시를 보내는 경우는 상관없지만, 대용량의 푸시를 보내야 한다면, 동기 처리 방식으로 푸시 알림을 보내기 때문에, 푸시를 보내기 위해 대기하는 요청이 쌓이게 됩니다. 이 때문에 서버는 성능이 저하되고, 최악의 경우 서버가 다운되는 상황까지 직면합니다. 이 문제를 해결하기 위해서는 비동기 메시지 처리 방식인 Queue를 활용해야 합니다. 그럼 Queue란 무엇이며, 프로젝트에서 어떤 Queue를 활용해야 할지 정리하기 위해 글을 작성합니다.

메시지 큐
메시지 큐(Message Queue)는 프로세스 또는 프로그램 간에 데이터를 교환할 때 사용하는 통신 방법 중에 하나로, 메시지 지향 미들웨어(Message Oriented Middleware: MOM)를 구현한 시스템을 의미합니다. 메시지 지향 미들웨어(MOM)란 분산 시스템 간 메시지를 주고받는 기능을 지원하는 소프트웨어나 하드웨어 인프라를 의미합니다. 여기서 메시지란 요청, 응답, 오류 메시지 혹은 단순한 정보 등의 작은 데이터가 될 수 있습니다. 그리고 이런 MOM을 구현한 시스템을 메시지 큐라고 합니다.

메시지 큐의 기본적인 원리는, Producer(생산자)가 Message를 Queue에 넣어두면, Consumer가 Message를 가져와 처리하는 방식입니다. 메시지 큐를 활용하면 다음의 이점을 누릴 수 있습니다.
비동기(Asynchronous)
메시지 큐는 생산된 메시지의 저장, 전송에 대해 동기화 처리를 진행하지 않고, 큐에 넣어 두기 때문에 나중에 처리할 수 있습니다. 여기서, 기존 동기화 방식은 많은 메시지(데이터)가 전송될 경우 병목이 생길 수 있고, 뒤에 들어오는 요청에 대한 응답이 지연될 것입니다.
낮은 결합도(Decoupling)
생산자 서비스와 소비자 서비스가 독립적으로 행동하게 됨으로써 서비스 간 결합도가 낮아집니다.
확장성(Scalable)
생산자 서비스 혹은 소비자 서비스를 원하는 대로 확장할 수 있기 때문에 확장성이 좋습니다.
탄력성(Resilience)
소비자 서비스가 다운되더라도 애플리케이션이 중단되는 것은 아닙니다. 메시지는 메시지 큐에 남아 있습니다. 소비자 서비스가 다시 시작될 때마다 추가 설정이나 작업을 수행하지 않고도 메시지 처리를 시작할 수 있습니다.
보장성(Guarantees)
메시지 큐는 큐에 보관되는 모든 메시지가 결국 소비자 서비스에게 전달된다는 일반적인 보장을 제공합니다.
비동기, 낮은 결합도, 확장성, 탄력성, 보장성 등의 이점이 있는 메시지 큐를 활용할 수 있는 시스템을 브로커라고 합니다. 이런 브로커는 크게 메시지 브로커와 이벤트 브로커로 나눌 수 있습니다.

메시지 브로커와 이벤트 브로커
메시지 브로커는 publisher가 생산한 메시지를 메시지 큐에 저장하고, 저장된 데이터를 consumer가 가져갈 수 있도록 중간 다리 역할을 해주는 브로커(broker)라고 볼 수 있습니다. 보통 서로 다른 시스템(혹은 소프트웨어) 사이에서 데이터를 비동기 형태로 처리하기 위해 사용합니다. 이러한 구조를 보통 pub/sub 구조라고 하며 대표적으로 RabbitMQ 소프트웨어가 있고 AWS의 SQS 같은 서비스가 있습니다. 이와 같은 메시지 브로커들은 consumer가 큐에서 데이터를 가져가게 되면 즉시 혹은 짧은 시간 내에 큐에서 데이터가 삭제되는 특징들을 가지고 있습니다.
이벤트 브로커는 기본적으로 메시지 브로커의 큐 기능들을 가지고 있습니다. 그래서 이벤트 브로커는 메시지 브로커의 역할을 할 수 있지만 메시지 브로커는 이벤트 브로커의 역할을 할 수 없습니다. 이벤트 브로커는 publisher가 생산한 이벤트를 데이터베이스에 저장하듯이 계속 저장하여, 후에 consumer가 특정 시점부터 이벤트를 다시 읽어갈 수 있습니다. (예를 들어 장애가 일어난 시점부터 그 이후의 이벤트들을 다시 처리할 수 있습니다.) 이것이 메시지 브로커와 가장 큰 차이라고 볼 수 있습니다. 또한 대용량 데이터 처리에 있어서 메시지 브로커보다는 더 많은 양의 데이터를 처리할 수 있는 능력이 있습니다.
RabbitMQ
메시지 브로커에는 대표적으로 RabbitMQ가 있습니다. RabbitMQ는 AMQP 프로토콜을 구현한 메시지 브로커라고 합니다. 여기서 AMQP란 무엇일까요?
AMQP란 Advanced Message Queueing Protocol의 줄임말로 MQ의 오픈소스에 기반한 표준 프로토콜을 의미합니다. AMQP는 마지막 P에서 보는 것과 같이 프로토콜을 의미하기 때문에 이 것을 사용한 가장 유명한 소프트웨어는 RabbitMQ라 볼 수 있습니다. AMQP를 구성하는 요소는 Exchange, Queue, Binding이 있습니다.

Exchange
Exchange는 생산자로부터 수신한 메시지를 적절한 큐나 다른 exchange로 분배하는 라우터의 기능을 합니다. Exchange는 수신한 메시지를 분배하기 위해 Exchange Type이라 하는 라우팅 알고리즘을 사용합니다. 브로커는 여러 개의 Exchange Type 인스턴스를 가질 수 있습니다.
Exchange Type을 아래의 Binding과 혼동할 수 있는데 Exchange Type은 받은 메시지를 어떤 방법으로 라우팅 할지 결정하는 것이고 Binding은 이러한 방법으로 결정된 메시지를 어느 Queue에 전달할지 결정하는 라우팅 테이블입니다.
예를 들어, 주소 정보를 받는 브로커가 존재하면 해당 주소 정보의 시, 도를 보고 Queue를 결정하는 방식을 Exchange Type이라 하고 서울은 1번 Queue, 인천은 2번 Queue 등과 같이 큐를 결정하는 것이 Binding입니다.
메시지 브로커에서 큐에 메시지를 전달하는 역할을 합니다.
Queue
메모리나 디스크에 메시지를 저장하고, 그것을 소비자에게 전달하는 역할을 합니다.
Binding
Exchange와 Queue와의 관계를 정의한 일종의 라우팅 테이블입니다. 동일한 Queue가 여러 개의 Exchange에 Binding 될 수도 있고 단일 Exchange에 여러 개의 큐가 Binding 될 수도 있습니다. Exchange에 전달된 메시지가 어떤 큐에 저장되어야 하는지를 정의합니다.

그럼 RabbitMQ는 AMQP를 기반으로 둔 소프트웨어이기 때문에 위에서 설명한 내용을 그대로 따라갑니다. Queue는 소비자에게 메시지를 전달한 후 ACK을 받았을 때, 해당 메시지를 dequeue 합니다. 소비자가 ACK을 Queue에 전달하지 못하는 경우는 받은 메시지가 너무 커 아직 처리 중이거나 소비자 서버가 죽었을 때입니다. RabbitMQ에서는 ACK을 받지 못한 메시지의 경우, 대기를 하고 있다가 전달한 소비자 서버의 상태를 확인한 후, Disconnected와 같은 신호를 받았을 경우 해당 소비자를 제외하고 다른 소비자에게 동일한 메시지를 전달합니다.
만약 메시지를 Queue에 넣은 다음 소비자에게 전달하기 전에 RabbitMQ 서버가 죽는다면 Queue는 메모리에 데이터를 쓰는 형식이므로 모든 데이터가 소멸하게 됩니다. 이러한 문제를 해결하기 위해 영속성이란 개념을 가지고 있습니다. Message Durability는 메시지가 Queue에 저장될 때, disk의 파일에도 동시에 저장하는 방법입니다. 해당 방법을 사용하면 서버가 죽었을 때, Queue의 데이터가 어느 정도 복구가 되지만 메시지가 disk의 파일에 쓰는 도중에 서버가 죽는 경우도 있어서 일부 데이터의 소실이 발생할 수 있습니다.
이런 RabbitMQ에는 다음의 특징이 있습니다.
- AMQT 프로토콜을 구현해놓은 프로그램
- 신뢰성 – 안정성과 성능을 충족할 수 있도록 다양한 기능 제공
- 유연한 라우팅 – Message Queue가 도착하기 전에 라우팅 되며 플러그인을 통해 더 복잡한 라우팅 가능
- 클러스터링 – 로컬 네트워크에 있는 여러 RabbitMQ 서버를 논리적으로 클러스터링 할 수 있고 논리적인 브로커도 가능하다.
- 관리 UI가 있어 편하게 관리 가능하다
- 거의 모든 언어와 운영체제 지원
- 오픈소스이며 상업적 지원
Kafka
이벤트 브로커에는 대표적으로 Kafka가 있습니다. kafka는 LinkedIn에서 개발된 메시지큐 방식 기반, 분산 메시징 시스템입니다. kafka의 기본 동작 원리를 그림을 통해 이해하자면 아래와 같은 특징이 있습니다.

kafka는 pub-sub 모델 기반으로 크게 보자면 publisher(=producer), subscriber(=consumer), kafka cluster로 구성됩니다.
위 그림을 참고하여 kafka의 특징을 정리하면 아래와 같습니다.
- 분산 시스템을 기본으로 설계되었기 때문에, 기존 메시징 시스템에 비해 분산 및 복제 구성을 손쉽게 할 수 있다.
- 메시지를 기본적으로 메모리에 저장하는 기존 메시징 시스템과는 달리 메시지를 파일 시스템에 저장한다.
- 파일 시스템에 메시지를 저장하기 때문에 별도의 설정을 하지 않아도 데이터의 영속성(durability)이 보장된다.
- 기존 메시징 시스템에서는 처리되지 않고 남아있는 메시지의 수가 많을수록 시스템의 성능이 크게 감소하였으나, Kafka에서는 메시지를 파일 시스템에 저장하기 때문에 메시지를 많이 쌓아두어도 성능이 크게 감소하지 않는다. 또한 많은 메시지를 쌓아둘 수 있기 때문에, 실시간 처리뿐만 아니라 주기적인 batch작업에 사용할 데이터를 쌓아두는 용도로도 사용할 수 있다.
- Consumer에 의해 처리된 메시지(acknowledged message)를 곧바로 삭제하는 기존 메시징 시스템과는 달리 처리된 메시지를 삭제하지 않고 파일 시스템에 그대로 두었다가 설정된 수명이 지나면 삭제한다. 처리된 메시지를 일정 기간 동안 삭제하지 않기 때문에 메시지 처리 도중 문제가 발생하였거나 처리 로직이 변경되었을 경우 consumer가 메시지를 처음부터 다시 처리(rewind)하도록 할 수 있다.
- 기존의 메시징 시스템에서는 broker가 consumer에게 메시지를 push 해 주는 방식인데 반해, Kafka는 consumer가 broker로부터 직접 메시지를 가지고 가는 pull 방식으로 동작한다. 따라서 consumer는 자신의 처리능력만큼의 메시지만 broker로부터 가져오기 때문에 최적의 성능을 낼 수 있다.
- 기존의 push 방식의 메시징 시스템에서는 broker가 직접 각 consumer가 어떤 메시지를 처리해야 하는지 계산하고 어떤 메시지를 처리 중인지 트랙킹 하였는데, Kafka에서는 consumer가 직접 필요한 메시지를 broker로부터 pull 하므로 broker의 consumer와 메시지 관리에 대한 부담이 경감되었다.
- 메시지를 pull 방식으로 가져오므로, 메시지를 쌓아두었다가 주기적으로 처리하는 batch consumer의 구현이 가능하다.
어떤 브로커를 활용할까?
메시지 브로커와 이벤트 브로커 중 어떤 브로커를 활용해야 할까요? 다시 kafka와 RabbitMQ에 대해 정리해보면 다음과 같습니다.
Kafka
- pub/sub방식은 생산자 중심적인 설계로 구성. 생성자가 원하는 각 메시지를 게시할 수 있도록 하는 메시지 배포 패턴으로 진행
- 생성자로부터 메시지가 들어오면 해당 메시지를 topic으로 분류하고 이를 event streamer에 저장한다. 그 후, 수신인이 특정 topic에 대한 메시지를 가져가더라도 event streamer는 해당 topic을 계속 유지하기 때문에 특정 상황이 발생하더라도 재생이 가능하다.
- 클러스터를 통해 병렬 처리가 주요 차별점인 만큼 방대한 양의 데이터를 처리할 때, 장점이 부각된다.
RabbitMQ
- 메시지 브로커 방식은 브로커 중심적인 설계로 구성. 지정된 수신인에게 메시지를 확인, 라우팅, 저장 및 배달하는 역할을 수행하며 보장되는 메시지 전달에 초점
- queue에 저장되어 있던 메시지에 대해 Event Consumer가 가져가게 되면 queue에서 해당 메시지를 삭제한다.
- 데이터 처리보단 Manage UI를 제공하는 만큼 관리적인 측면이나, 다양한 기능 구현을 위한 서비스를 구축할 때, 장점이 부각된다.
분산/대용량/고성능/노드 장애 대응 4가지 목적이 필요하면 카프카를 사용하면 좋겠지만, 지금은 큐를 잘 관리할 수 있는 메시지 브로커를 선택하는 것이 프로젝트 진행에 있어서 좋겠다고 생각했습니다. 특히 관리 UI가 있다는 부분에 있어서는 큐를 조금 더 유용하게 사용할 수 있겠다고 생각했습니다. 카프카는 지금 상황에서는 오버스펙이라고 생각했습니다.

어떤 메시지 브로커를 활용할까?
그럼, 위에서는 메시지 브로커와 이벤트 브로커 중 어떤 것을 활용해야 할지 알아봤다면, 이제는 메시지 브로커 중에서도 어떤 브로커를 활용해야 할지 알아보겠습니다. 메시지 브로커도 너무나 많은 것들이 존재하고 있지만, 관리를 할 때 돈이 최대한 들어가지 않는 서비스를 먼저 이용하는 것이 좋다고 생각했습니다. 이를 위해 RabbitMQ와 Redis Queue를 구축했을 때 초기에 관리 비용이 얼마나 들어갈 수 있는지 알아봤습니다.
먼저 서버가 장애가 나더라도, 메시지 큐를 문제없이 관리할 수 있기 위해 현재 가동 중인 서버와 메시지 큐를 분리하는 것을 목표로 잡았습니다.
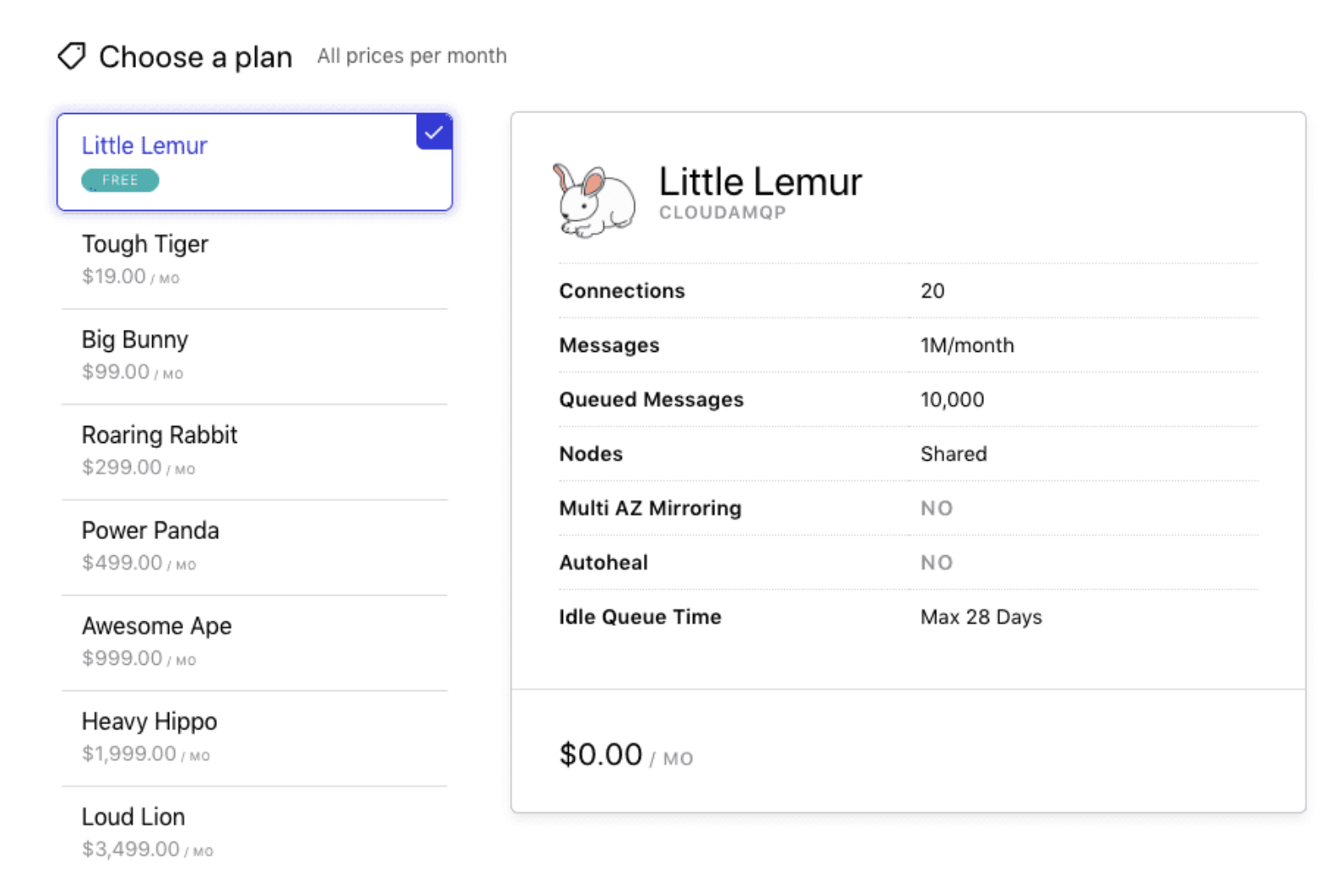
그래서 RabbitMQ에서는 CloudAMQP를 활용하는 방법이 있었고, Redis의 경우 AWS ElastiCache를 활용하는 방법이 있었습니다. 그중, RabbitMQ의 경우, 무료 플랜이 큐에 메시지가 10,000개까지 활용할 수 있는데 비해

AWS ElastiCache의 경우 t2.micro의 캐시 노드를 제한 없이 이용할 수 있었습니다. 저희 서비스는 한 달에 10,000개의 메시지 그 이상으로 활용해야 했기에, Redis를 활용해서 큐를 구축하는 것이 최선이라고 생각했습니다. (AWS의 SQS도 이용가능했습니다. SQS를 통해 매달 1백만 건의 큐 요청을 무료로 사용할 수 있지만, 저희 서비스는 그 이상으로 큐를 사용할 것이라 판단했기에 SQS 또한 선택할 수 없었습니다.)그럼, Redis를 활용해서 큐를 구축하기 위해서는 어떤 것을 활용할 수 있을까요? 이에 대해 알아보겠습니다.

Bull을 활용하자
Node.js에서 Queue를 활용하기 위한 도구는 다양했습니다. 여기서 Redis 기반이면서, 사용성이 좋은 Bull을 활용해보고자 했습니다. Bull에서도 Bullmq-Pro, Bullmq, Bull 등 다양하게 존재하지만, Bullmq-Pro, Bullmq의 경우 큐 관리를 위해서는 일정 정도의 돈을 지불해야 하는데, Bull의 경우 돈을 지불하지 않아도 다양한 라이브러리를 활용할 수 있어서 장점이 있었습니다. 하지만 다른 Bull에 비해 기능은 조금 떨어지는 부분은 있었지만, 서비스 구축에 아직까지는 큰 문제가 되지 않는다고 생각했습니다.

공식 UI 대시보드가 없다는 점이 불편했지만, bull-board 라이브러리를 활용하면 처리 중인 작업 개수 정도는 확인이 가능했습니다.
GitHub - felixmosh/bull-board: 🎯 Queue background jobs inspector
🎯 Queue background jobs inspector . Contribute to felixmosh/bull-board development by creating an account on GitHub.
github.com
설치
본격적으로 bull를 활용해 보도록 하겠습니다. NestJS는 기본으로 @nestjs/bull을 제공합니다. 기존 Bull Queue를 Nest적인 방식으로 애플리케이션에 쉽게 통합할 수 있습니다.
$ npm install --save @nestjs/bull bull
$ npm install --save-dev @types/bull
nestjs에서 제공하는 bull을 설치합니다. 그 후 로컬에서 레디스를 활용하기 위해 도커를 이용해서 레디스를 아래와 같이 설정합니다.
$ docker pull redis
$ docker network create redis-net
$ docker run --name redis -p 6379:6379 --network redis-net -d redis redis-server --appendonly yes
Producer
그 후 BullModule을 등록합니다.
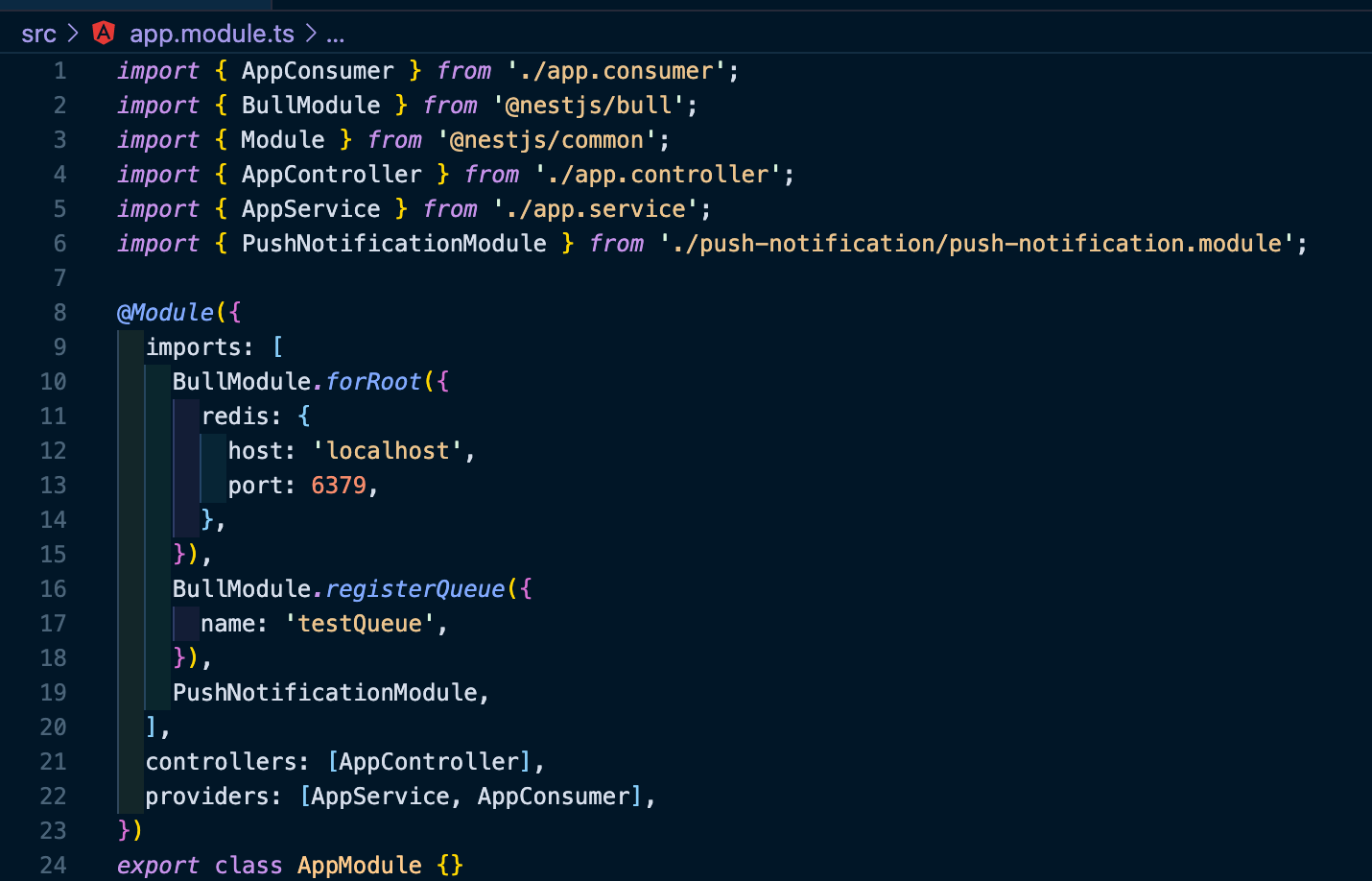
app.module.ts에 다운로드한 Bull Module을 import 하고, 추가적으로 큐의 이름을 'testQueue'로 지정하여 등록합니다.

그 후 AppController에 number 타입의 data를 입력받아 queue에 추가하는 API를 생성합니다.
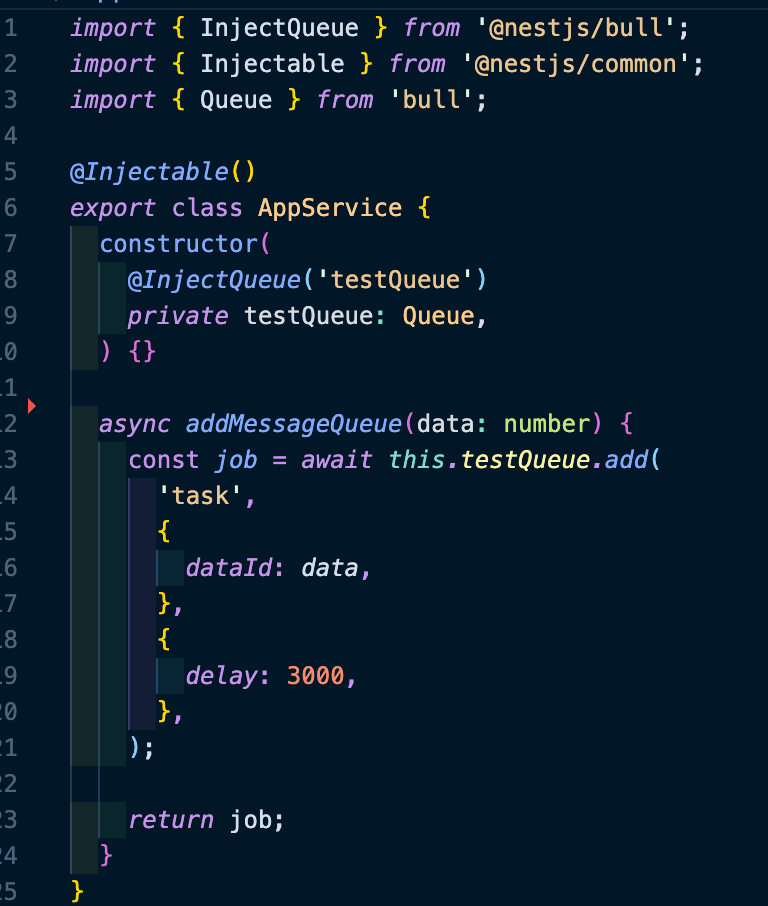
Service에서는 InjectQueue() 데코레이터를 통해 큐를 추가합니다. app.module.ts에서 BullModule.registerQueue()를 통해 등록했던 큐 이름으로 작성합니다. 그 후 add 메서드를 사용하여 해당 큐에 데이터를 넣습니다. 큐를 활용할 때 작업 옵션을 지정할 수 있습니다. delay를 활용해서, 딜레이 시간만큼 대기한 후 작업을 처리하게 만들었습니다. bull에는 이 외에도 다양한 작업 옵션을 지정할 수 있습니다. 이는 공식 문서를 통해 살펴볼 수 있습니다.

Postman을 통해 API를 테스트하면 다음과 같이 응답이 옵니다. task란 작업명으로 데이터가 정상적으로 추가되었습니다.
Consumer
지금까지 작업을 등록했으니, 작업을 처리하는 클래스를 생성하겠습니다.

Processor 데코레이터를 통해 수신할 큐 이름을 지정합니다. Process 데코레이터를 이용해서 수신할 작업명을 지정합니다. 수신 후, 해당 데이터를 Logger로 출력할 수 있게 코드를 작성했습니다.

그 후 app.module.ts의 providers에 AppConsumer를 추가해줍니다. 그 후에 포스트맨으로 API를 요청하면, 3초 뒤에 Logger가 찍힙니다.

마치며
앞으로도 팀의 발전을 돕는 개발자가 되기 위해 노력하려 합니다. 팀에 필요한 부분이 무엇일지 고민하면서, 팀에 도움이 된다면, 열심히 공부해서 실무에 적용할 수 있는 개발자가 되기 위해 노력하고 싶습니다. 팀의 성장에 기여할 수 있는 개발자가 되겠습니다.
참고 및 출처
메시지 큐(Message Queue) 훑어보기
이번글은 메시지 큐에 대한 개념과 여러가지 미들웨어를 훑어보기 위한 글 입니다. 웹 서버를 구성하게 되면 성능에 대한 고려는 빼먹을 수 없습니다. 데이터 처리를 하다보면 너무 많은 처리
heowc.tistory.com
메시지 큐에 대해 알아보자!
메시지 큐란 메시지 큐(Message Queue)는 프로세스 또는 프로그램 간에 데이터를 교환할 때 사용하는 통신 방법 중에 하나로, 메시지 지향 미들웨어(Message Oriented Middleware:MOM…
tecoble.techcourse.co.kr
최신 메시지 큐(Messgae Queue) MQ 기술
메시지 큐 란 무엇인가?메시지 지향 미들 웨어(Message Oriented Middleware: MOM)은 비 동기 메시지를 사용하는 다른 응용 프로그램 사이에서 데이터의 송수신을 의미 한다. MOM을 구현한 시스템을 메시지
kji6252.github.io
[NestJS] Redis Message Queue 구현해보기
Bull Queue를 이용한 메시지큐 튜토리얼
donis-note.medium.com
Documentation | NestJS - A progressive Node.js framework
Nest is a framework for building efficient, scalable Node.js server-side applications. It uses progressive JavaScript, is built with TypeScript and combines elements of OOP (Object Oriented Progamming), FP (Functional Programming), and FRP (Functional Reac
docs.nestjs.com
NodsJS - BullMQ 사용 (대기열, 동시성 제어 등)
BullMQ BullMQ는 Redis를 기반으로 하고, kafka나 RabbitMQ보다 훨씬 가볍고 편리한 Message queue입니다. 현재 기준 Github Star 11.8K 정도 되고, 거의 매일같이 커밋이 올라오는 뜨거운 라이브러리입니다. 제..
jaehoney.tistory.com
Kafka(이벤트 브로커) vs RabbitMQ(메시지 브로커)
kafka와 rabbitmq 모두 pub/sub 기반의 메시지 큐 서비스를 제공합니다.기존에는 rabbitmq보다 kafka에서 더 많은 기능 지원을 한다 정도만 알고 있었는데요.이벤트 기반 MSA를 공부하면서 kafka와 rabbitmq에
velog.io
카프카(kafka) vs RabbitMQ
오늘은 kafka와 RabbitMQ의 차이에 대해 알아보도록 하겠다. 1. 이해 1-1. 메시지 큐(MessageQuque : MQ) kafka와 rabbitMQ를 이해하기 위해선 우선 메시지 큐에 대한 이해가 선제적으로 필요하다. >메시지 큐(Mes
velog.io
Kafka 사용이유 ( vs RabbitMQ )
카프카를 사용하기전에 과연 어떤 곳에 카프카를 사용해야 하는가에 대한 기본적인 분석이 간단하게라도 필요하다고 생각이 들었다. RabbitMQ 보단 카프카가 빠르니 카프카를 쓰자 !! 혹은 더 단
ellune.tistory.com
RabbitMQ vs Redis | Top 9 Differences You Should Know
Guide to RabbitMQ vs Redis. Here we discuss the RabbitMQ vs Redis introduction, key differences with infographics and comparison table.
www.educba.com
(번역) RabbitMQ 및 Node.js를 사용한 비동기 마이크로 서비스
메세지와 이벤트를 통한 확장성과 내결함성.이 글은 Asynchronous Microservices with RabbitMQ and Node.js를 번역한 글입니다
velog.io
RabbitMQ란?
RabbitMQ는 AMQP 프로토콜을 구현한 메시지 브로커입니다. 생산자에게 메시지를 받아 소비자에게 전달해주는 서비스로 시스템 간 메시지를 전달해주는 오픈소스 메시지 브로커 소프트웨어입니다.
brownbears.tistory.com
CloudAMQP - RabbitMQ as a Service
CloudAMQP - industry leading RabbitMQ as a service Start your managed cluster today. CloudAMQP is 100% free to try.
www.cloudamqp.com
'Project > 서버 개발' 카테고리의 다른 글
| [Project] 프로젝트 삽질기11 (feat pgAdmin4) (0) | 2022.03.28 |
|---|---|
| [Project] 프로젝트 삽질기10 (feat bull 공식문서 정리) (0) | 2022.03.16 |
| [Project] 프로젝트 삽질기8 (feat ormConfig) (0) | 2022.03.15 |
| [Project] 프로젝트 삽질기7 (feat ORM 비교) (4) | 2022.03.13 |
| [Project] 프로젝트 삽질기6 (feat PostgreSQL 버전) (0) | 2022.03.11 |



