
들어가며
NestJS와 TypeORM을 활용하여 프로덕트를 만들고 있습니다. 제가 개발하고 있는 서비스에는 채팅 기능이 존재합니다. 유저가 서비스 내에서 채팅을 할 때 생성된 데이터는 Firebase의 Firestore에 저장하고 있습니다.
한 번은, 사용자들이 언제, 어느 시간대에 채팅을 하는지와 관련된 행동 데이터를 분석하고 싶었습니다. 데이터를 분석하려면 Firestore의 데이터를 모두 조회해야 했는데, 전체 데이터를 조회하는 과정이 상당히 번거로웠습니다. 만약 Firestore에 저장된 데이터를 BigQuery로 옮긴다면, 보다 빠르고 효율적으로 채팅 데이터를 분석할 수 있다고 판단했습니다. Firestore의 데이터를 BigQuery로 옮기는 과정에서 Cloud Functions를 사용했습니다. 그럼 어떻게 Firestore에 데이터가 저장되어 있으며, Firestore에 있는 데이터를 어떻게 BigQuery로 옮겼는지에 대해 정리해 보면 좋겠다고 생각했습니다.
이번 글을 통해 Firestore, BigQuery, 그리고 Cloud Functions를 어떻게 활용했는지 정리하려 합니다.

Firestore
위에서 채팅 데이터를 Firestore에 저장하고 있다고 했는데요. 먼저 Firestore란 무엇인지 간단히 정리해 보겠습니다.
Cloud Firestore는 Firebase 및 Google Cloud의 모바일, 웹, 서버 개발에 사용되는 NoSQL 데이터베이스 서비스입니다. 클라이언트 애플리케이션 간에 데이터의 동기화를 유지하고, 모바일 및 웹에 대한 오프라인 지원을 제공해 기기가 오프라인 상태가 되더라도 앱에서 데이터를 쓰고 읽고 수신 대기하고 쿼리 할 수 있습니다.
주요 기능
Firestore에서는 크게 5가지의 기능이 있습니다. 공식 문서에서는 아래와 같이 설명합니다.
| 유연성 | Cloud Firestore 데이터 모델은 유연한 계층적 데이터 구조를 지원합니다. 컬렉션으로 정리되는 문서에 데이터를 저장하세요. 하위 컬렉션 외에도 복잡한 중첩된 개체를 문서에 포함할 수 있습니다. |
| 표현형 쿼리 | Cloud Firestore에서는 쿼리를 사용해 개별 문서를 가져오거나 쿼리 매개변수와 일치하는 컬렉션의 모든 문서를 가져올 수 있습니다. 쿼리에 여러 필터를 서로 연결해 적용할 수 있으며 필터링과 정렬의 결합도 가능합니다. 또한 기본적으로 색인이 생성되어 쿼리 성능이 데이터 세트가 아닌 결과 세트의 크기에 비례합니다. |
| 실시간 업데이트 | 실시간 데이터베이스와 마찬가지로 Cloud Firestore는 데이터 동기화를 사용해 연결된 모든 기기의 데이터를 업데이트합니다. 더불어 간단한 일회성 가져오기 쿼리도 효율적으로 할 수 있도록 설계되었습니다. |
| 오프라인 지원 | Cloud Firestore는 앱에서 많이 사용되는 데이터를 캐시하기 때문에 기기가 오프라인 상태더라도 앱에서 데이터를 쓰고 읽고 수신 대기하고 쿼리할 수 있습니다. 기기가 온라인 상태로 전환되면 Cloud Firestore에서 모든 로컬 변경사항을 다시 Cloud Firestore로 동기화합니다. |
| 확장형 설계 | Cloud Firestore에서는 자동 멀티 리전 데이터 복제, 강력한 일관성 보장, 원자적 일괄 작업, 실제 트랜잭션 지원 등 Google Cloud의 강력한 인프라를 최대한 활용합니다. Cloud Firestore는 세계 최대 규모의 앱에서 수많은 데이터베이스 워크로드를 처리하도록 설계되었습니다. |
위 기능을 살펴보면서, Firestore를 활용하면, 유저가 오프라인 상태에서도 예전에 작성한 채팅 데이터를 살펴볼 수 있어서 사용자 경험에 좋다고 판단했고, 별도 서버 자원이 필요하지 않기 때문에 클라이언트 개발자가 빠르게 채팅 기능을 개발할 수 있다고 판단했으며, 더 나아가 채팅 데이터에 대량의 트래픽이 아직은 발생하지 않으니 간단히 채팅 기능을 구현하는데 큰 도움이 될 수 있다고 판단했습니다.
그럼 Firestore는 어떤 구조로 데이터를 저장하고 관리하는지 간단히 살펴보겠습니다. Firestore의 기본 구조는 아래와 같습니다.
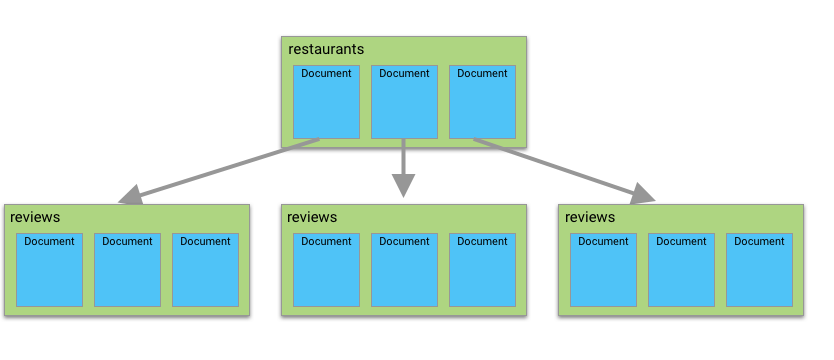
기본 구조
Cloud Firestore은 컬렉션(collection)과 도큐먼트(document)로 구성된 트리구조로 이뤄져 있습니다. 컬렉션은 도큐먼트를 저장하는 공간이고, 도큐먼트는 딕셔너리 형태로 자료를 저장하는 공간입니다. SQL 테이블로 비교하자면 도큐먼트는 테이블의 한 행, 즉 데이터이고 데이터별로 그룹화해서 컬렉션에 저장하는 구조입니다.
도큐먼트에는 키와 값의 쌍들로 구성됩니다. Firestore는 키를 필드(field)라고 부릅니다. 필드의 값으로는 어떤 데이터 타입도 넣을 수 있고 맵 또는 배열(array)도 들어갈 수 있습니다.
Firestore의 컬렉션 안에 도큐먼트가 있고, 도큐먼트 하위에 컬렉션이 존재하며, 하위 컬렉션에 도큐먼트가 존재하도록 구성할 수 있습니다. 만약 원하는 데이터를 조회하려면 컬렉션 -> 도큐먼트 -> 컬렉션 -> 도큐먼트의 순서로 접근해야 합니다.
컬렉션과 도큐먼트는 다음과 같은 규칙을 따릅니다.
- 컬렉션은 도큐먼트만 가질 수 있다.
- 도큐먼트는 최대 1MB까지만 저장 가능하다.
- 도큐먼트는 다른 컬렉션을 가리킬 수 있지만, 다른 도큐먼트를 가리킬 수 없다.
- Firestore의 루트는 오직 컬렉션만 가질 수 있다.

저는 Firestore를 활용하여 채팅 데이터를 저장하고 관리할 때(위 사진은 전혀 무관한 사진입니다), 데이터에는 서로 채팅하고 있는 유저의 id, 채팅 내용, 채팅 시간 등을 기록하고 있습니다. 채팅 컬렉션에 유저의 채팅방 별로 도큐먼트가 존재하고, 도큐먼트 안에 채팅 데이터를 담기 위한 컬렉션이 존재하고, 각 채팅 데이터를 저장하는 도큐먼트가 존재합니다. 그래서 각 채팅 데이터를 조회하기 위해선, 채팅 컬렉션 -> 채팅방 도큐먼트 -> 채팅 데이터 컬렉션 -> 채팅 도큐먼트의 순서로 데이터를 조회해야 했습니다.
컬렉션에 존재하는 모든 채팅 데이터를 조회할 순 있지만, 쿼리가 빈약하다는 단점이 존재했고, Firestore만으로 데이터를 효율적으로 조회하기에는 어려움이 존재했습니다. 만약 9월에 생성된 채팅 데이터가 몇 개인지, 어떤 유저가 가장 많이 채팅을 했는지 등과 관련된 행동 데이터를 분석하려면 컬렉션 -> 도큐먼트 -> 컬렉션 -> 도큐먼트의 모든 데이터를 조회해야 하는데, 채팅 데이터가 많아질수록 이 과정은 상당히 부담으로 다가왔습니다.
그래서 Firestore에 존재하는 데이터를 효율적으로 조회하려면 어떻게 해야 할까 고민했고, Firestore에 있는 데이터를 BigQuery로 옮긴다면 SQL 쿼리문을 사용할 수 있기 때문에 데이터를 보다 효율적으로 조회할 수 있을 것이라 판단했습니다. 그래서 데이터를 이관하는 작업을 시작했습니다.
데이터를 이관하기 위해 아래의 작업들을 진행했습니다.
1. Firestore에 저장된 기존 데이터를 BigQuery로 적재한다.
2. Firestore에 저장되는 신규 데이터를 BigQuery로 적재한다.
3. BigQuery로 데이터를 조회한다.
위 순서대로, 어떻게 작업을 진행했는지 정리해 보겠습니다.

BigQuery
먼저 Firestore에 저장된 기존 데이터를 BigQuery에 적재하는 과정을 살펴보겠습니다. 그전에 BigQuery란 무엇인지 어떻게 사용할 수 있는지 간단히 정리하겠습니다.
먼저 BigQuery란, Google에서 드레멜 엔진을 사용해 만든 페타 바이트 규모의 저비용 데이터 웨어하우스입니다. 구글에서 관리해 주기 때문에 사용자가 별도의 서버나 물리적 하드웨어에 대해 스트레스를 받을 일이 없습니다. 일반적인 rdb나 NoSQL보다 속도가 월등히 빠르며, 몇 초 안에 TB를 스캔할 수 있습니다.
Firestore의 데이터를 BigQuery에 데이터를 적재하기 위해, 먼저 데이터 세트를 생성하고 데이터 세트에 테이블을 생성했습니다.
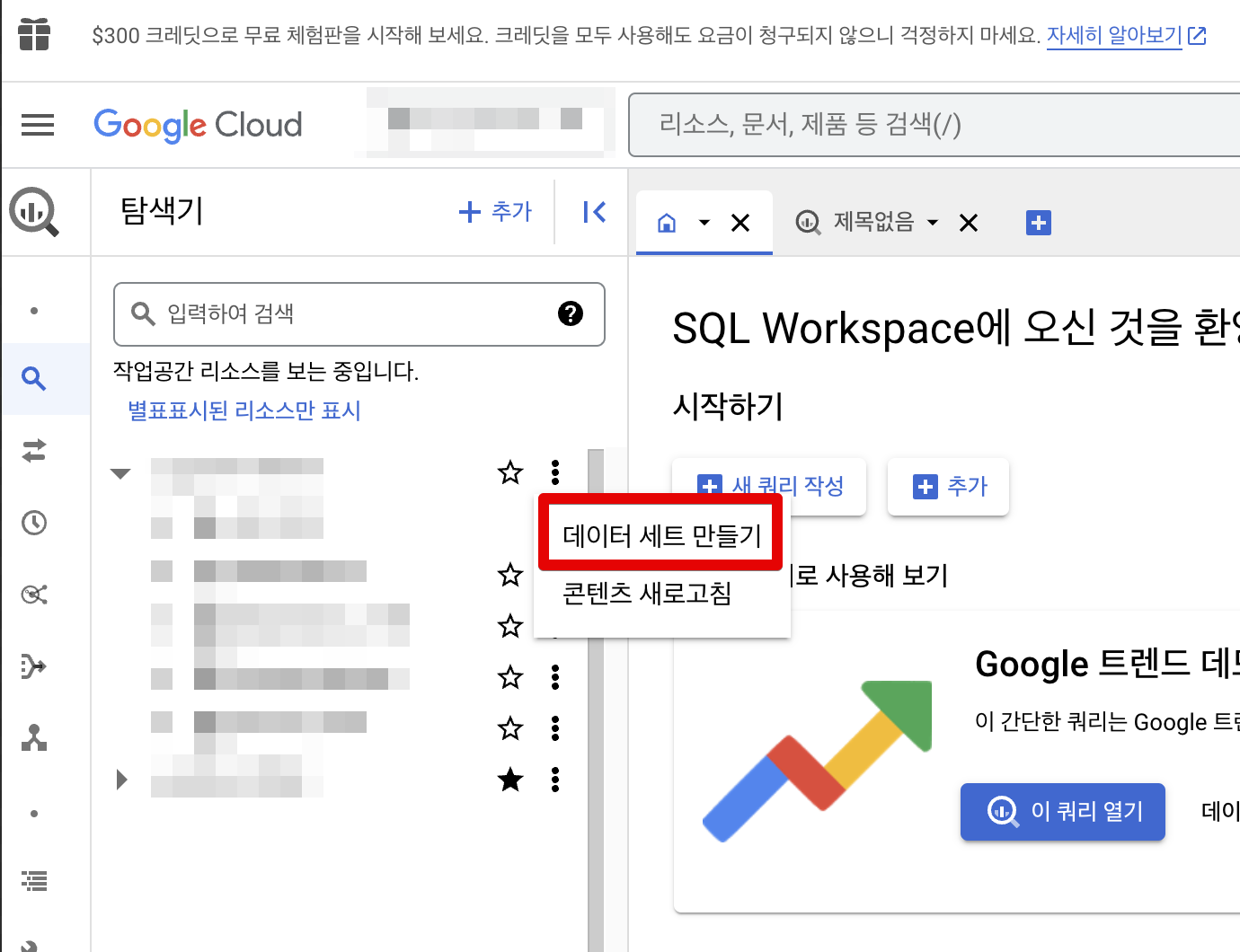
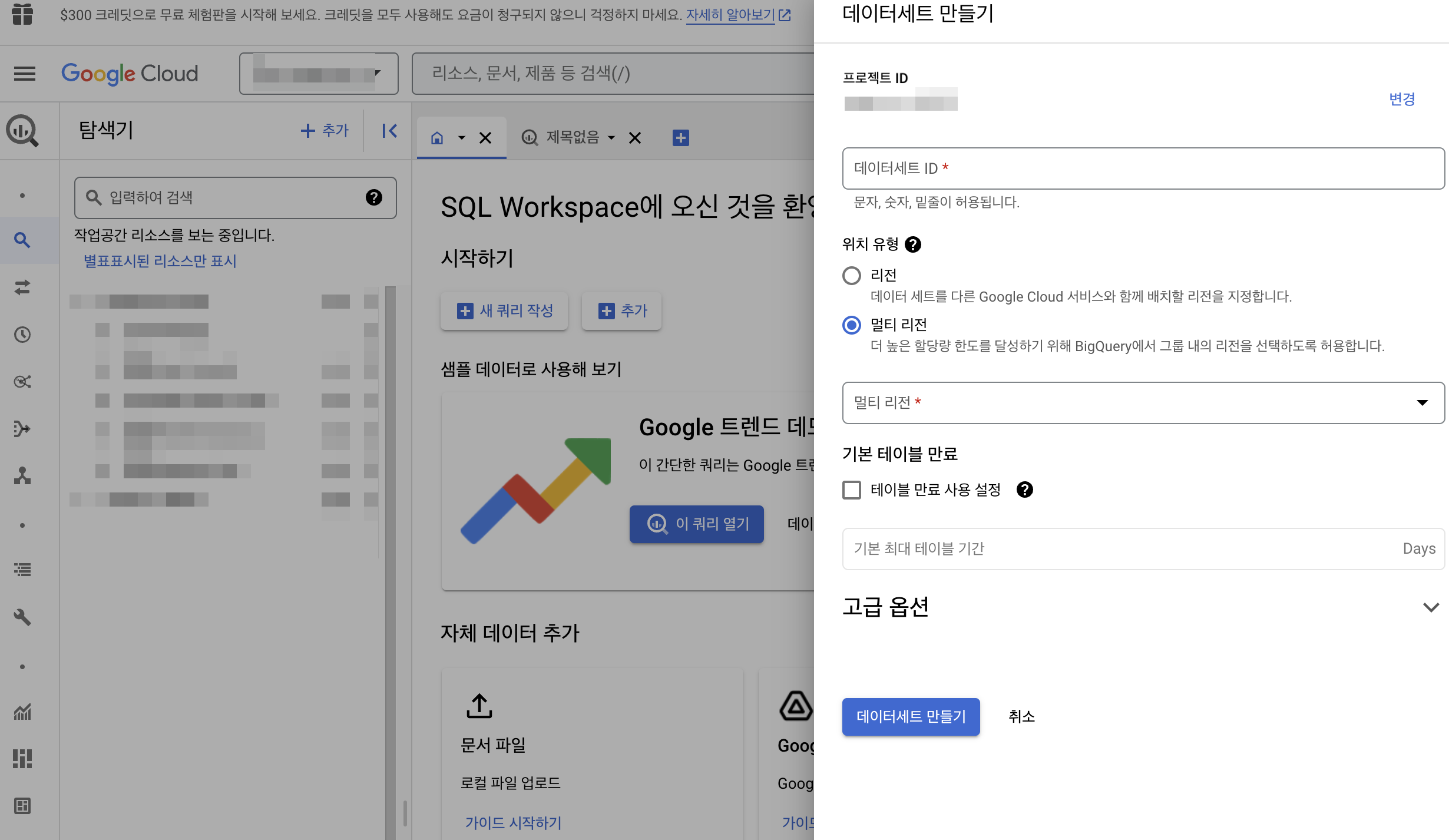
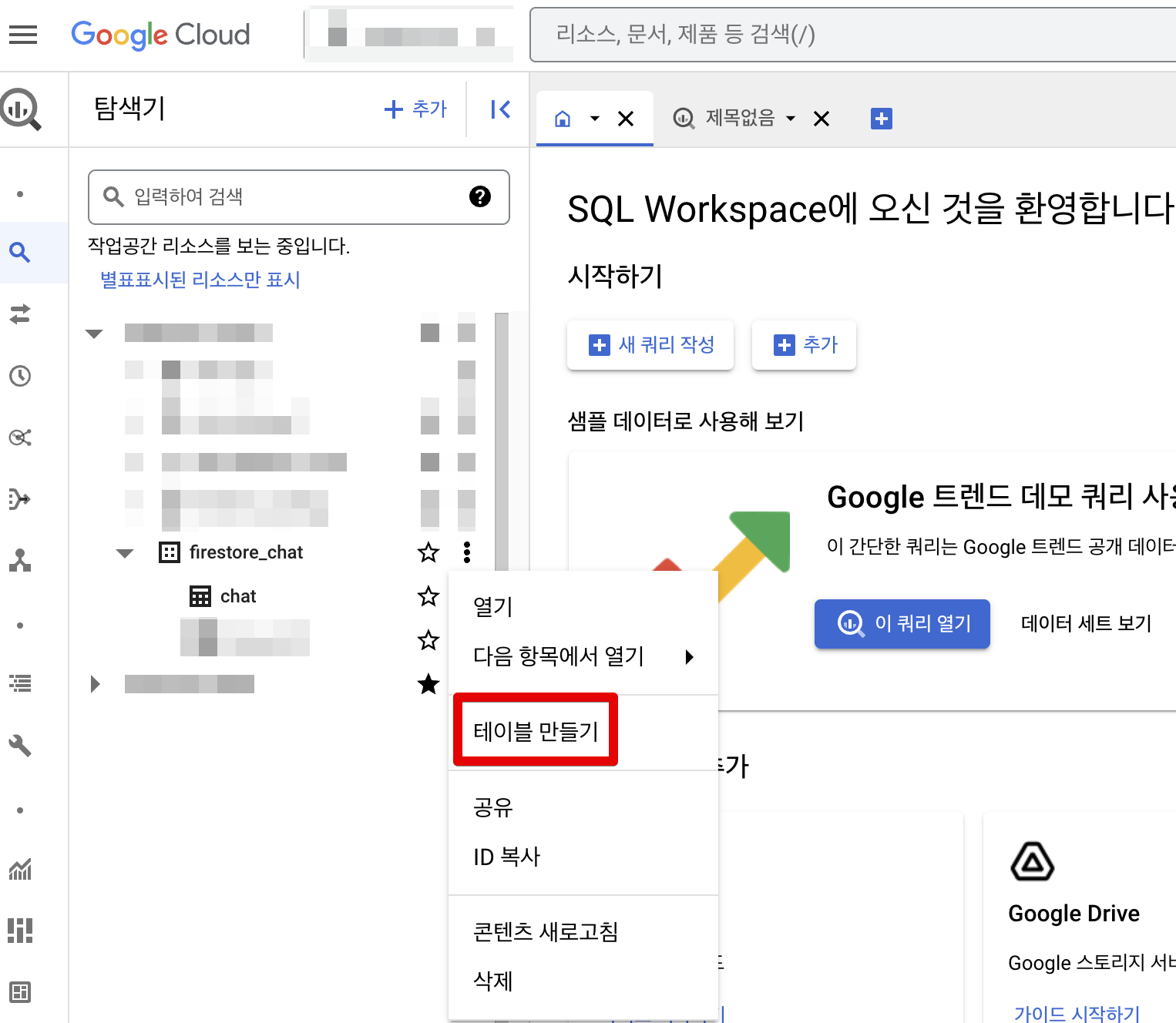
BigQuery 콘솔로 들어가서, 탐색기를 누르고, 작업공간에서 데이터세트를 만들 수 있습니다. firestore의 채팅 데이터를 저장하기 위해 firestore_chat이라는 데이터세트를 만들고, chat이라는 테이블을 생성했습니다. 그 후 Firestore의 데이터를 BigQuery로 적재하기 위해 Functions라는 기능을 사용했습니다.

Cloud Functions
cloud functions는 클라우드 서비스를 구현하고 연결하기 위해 구글 클라우드 플랫폼에서 제공하는 서버리스 컴퓨팅 서비스입니다. 이벤트가 발생하거나, 특정 시간마다 코드를 실행시킬 수 있는 완전 관리형 서비스입니다. functions를 활용하려면 Firebase를 Blaze 요금제를 사용해야 합니다. 해당 요금제를 사용하고 있다고 가정하고, 아래의 단계를 진행하시면 됩니다.
cloud functions를 활용하기 위해서는 먼저 라이브러리 설치가 필요합니다. node 및 npm이 설치되어 있다는 전제하에 아래 라이브러리를 설치하시면 됩니다.
npm install -g firebase-tools
위처럼 전역으로 라이브러리를 설치하고, 제대로 설치됐는지 확인하려면 아래의 명령어를 입력하시면 됩니다.
firebase --version

위처럼 버전 정보가 제대로 출력됐다면, 라이브러리가 정상적으로 설치가 완료되었습니다. firebase 라이브러리를 제대로 설치했다면, 이제 firebase를 cli 환경에서 활용하기 위해 로그인을 해야 합니다. 다른 서비스들은 인증키를 발급하고 관리해야 하지만, 파이어베이스는 로그인을 하면 되기 때문에 비교적 간편하면서 안전하게 서비스를 활용할 수 있습니다. 일단 아래처럼 로그인을 진행하시면 됩니다.
firebase login
위 명령어를 입력하면 아래와 같은 화면이 나오는데요.
허용 버튼을 클릭하면 됩니다. 로그인이 완료됐다면, 현재 firebase에 프로젝트가 존재하는지 확인해 봅니다. 확인하려면 아래 명령어를 입력해 줍니다.
firebase projects:list
만약 프로젝트가 존재하지 않는다면, 아래 명령어를 입력합니다.
firebase init functions
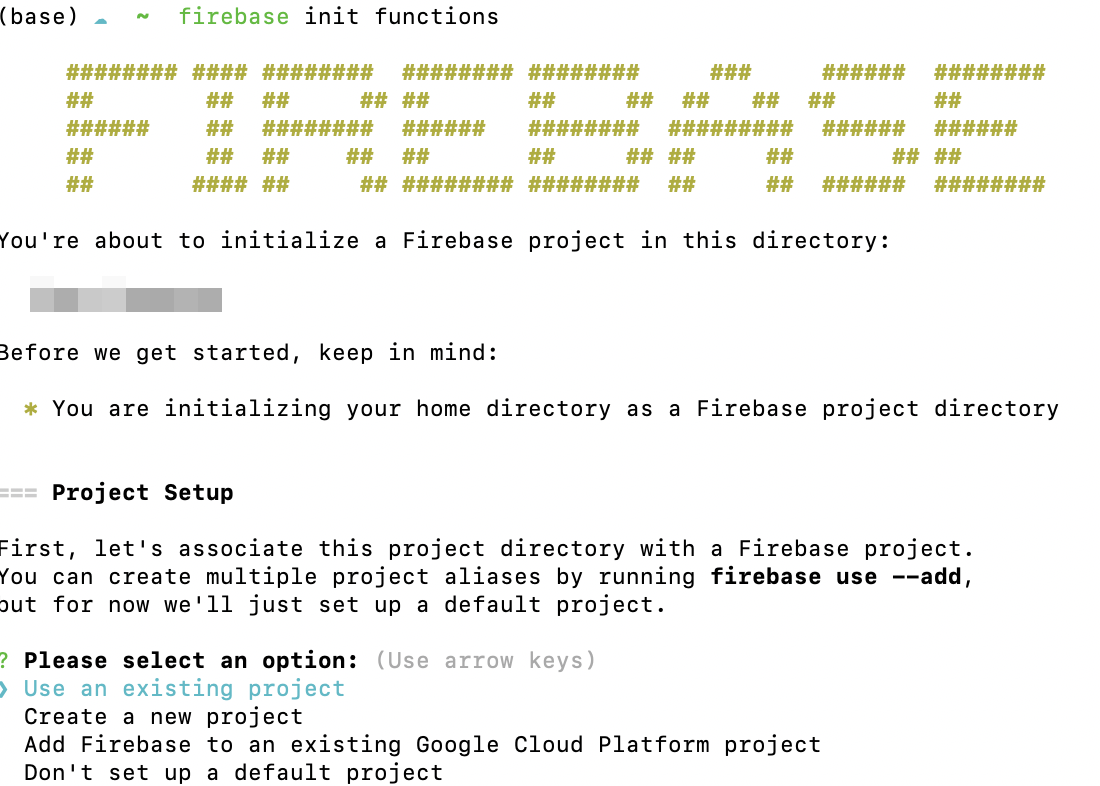
명령어를 입력하면 위와 같이 나오는데요. 저는 이미 만들어져 있는 프로젝트를 사용할 것이기 때문에 Use and Existing project 옵션을 선택했습니다. 프로젝트를 선택하면, 어떤 언어로 개발할지 나오는데, 저는 js를 선택했습니다. 그 후 ESLint를 세팅할 것인지, npm으로 의존성을 관리할 것인지 선택하는 화면이 나오는데, 여러분들이 원하는 옵션을 선택하시면 됩니다.
모두 설정을 완료했다면, 아래와 같은 구조로 파일이 생성될 것입니다.
위와 같이 설정이 완료됐다면, 기본적인 functions 세팅이 완료됐습니다. 그럼 이제 본격적으로 functions를 활용해서 firestore의 데이터를 BigQuery로 적재하는 로직을 살펴보겠습니다.
위에서 저는 3가지 작업을 처리해야 한다고 설명했습니다.
1. Firestore에 저장된 기존 데이터를 BigQuery로 적재한다.
2. Firestore에 저장되는 신규 데이터를 BigQuery로 적재한다.
3. BigQuery로 데이터를 조회한다.
이를 위해 먼저 첫 번째 작업인 Firestore에 저장된 기존 데이터를 BigQuery로 적재하는 로직을 살펴보겠습니다.
기존 데이터 BigQuery 적재
functions 로직은 아래와 같습니다.
const admin = require('firebase-admin');
const { BigQuery } = require('@google-cloud/bigquery');
admin.initializeApp({
credential: firebase 환경변수,
databaseURL: 'https://여러분들 url',
});
const firestore = admin.firestore();
const bigquery = new BigQuery();
async function handleSubCollection(datasetId, tableId, collection) {
const documentsSnapshot = await collection.get();
const rows = documentsSnapshot.docs.map((doc) => {
const data = doc.data();
const timestamp = new Date(parseInt(data.timestamp)).toISOString();
return {
idTo: data.idTo,
idFrom: data.idFrom,
timestamp: timestamp,
content: data.content,
};
});
await bigquery.dataset(datasetId).table(tableId).insert(rows);
console.log(`Sub-collection saved to BigQuery: ${collection.id}`);
}
exports.firestoreChatDataBackupForBigQuery = functions
.runWith({
timeoutSeconds: 540,
memory: '2GB',
})
.region('asia-northeast3')
.https.onRequest(async (req, res) => {
const collectionsRef = firestore.collection('여러분들의 컬렉션 이름');
const allCollectionsRef = await collectionsRef.get();
const allSubCollections = [];
for (const doc of allCollectionsRef.docs) {
const subCollections = await doc.ref.listCollections();
allSubCollections.push(...subCollections);
}
// 데이터셋 및 테이블 ID 설정
const datasetId = '여러분들의 빅쿼리 데이터 셋';
const tableId = '여러분들의 빅쿼리 데이터 셋 테이블 이름';
try {
for (const subCollection of allSubCollections) {
await handleSubCollection(datasetId, tableId, subCollection);
}
res.status(200).send('Data successfully saved to BigQuery');
} catch (error) {
res.status(500).send('Error occurred: ' + error);
}
});
firestoreChatDataBackupForBigQuery라는 function을 하나 임시로 만들었습니다. function을 실행할 때 타임아웃 설정을 처리했고, 대량의 데이터를 옮겨야 할 수 있기에 메모리 부족 문제가 나오지 않도록 메모리도 2GB를 사용하도록 임시 처리했습니다. 리전은 asia-northeast3으로 처리했고, 모든 서브 컬렉션을 처리한 후 결과를 HTTP 응답으로 반환합니다. 실패할 경우 에러 메시지를 반환하도록 설정했습니다.
함수를 실행하면 firestore의 특정 컬렉션에 있는 모든 도큐먼트를 조회합니다. 그 후 모든 도큐먼트의 하위 컬렉션을 조회합니다. 하위 컬렉션의 도큐먼트의 정보를 순서대로 조회해서 BigQuery에 분석에 필요한 데이터를 저장하도록 구성했습니다.
신규 데이터 BigQuery 적재
이 전에는 기존에 저장되어 있던 firestore 데이터를 BigQuery로 적재하는 과정을 살펴봤다면, 이번에는 신규데이터가 적재되면, 바로 BigQuery에 적재되도록 하는 로직을 functions으로 구성하겠습니다.
exports.firestoreChatNewDataSaveBigQuery = functions
.runWith({
timeoutSeconds: 60,
memory: '256MB',
})
.region('asia-northeast3')
.firestore.document('messages/{docId}/{subCollectionId}/{messageId}')
.onCreate(async (snap, context) => {
// 생성된 문서의 데이터 가져오기
const data = snap.data();
const messageId = context.params.messageId;
// 데이터셋 및 테이블 ID 설정
const datasetId = '여러분들의 데이터 셋';
const tableId = '여러분들의 table';
// 데이터를 필요한 필드로 줄이고 타임스탬프를 날짜 형식으로 변환합니다.
const timestamp = new Date(parseInt(data.timestamp)).toISOString();
const row = {
idTo: data.idTo,
idFrom: data.idFrom,
timestamp: timestamp,
content: data.content,
};
try {
// BigQuery에 데이터 저장
await bigquery.dataset(datasetId).table(tableId).insert(row);
console.log(`Document saved to BigQuery: ${messageId}`);
} catch (error) {
console.error('Error occurred: ' + error);
}
});
만약 messages라는 컬렉션의 하위 도큐먼트의 서브 컬렉션의 하위 도큐먼트가 생성될 때마다, BigQuery에 데이터가 저장되는 로직을 구성했습니다.
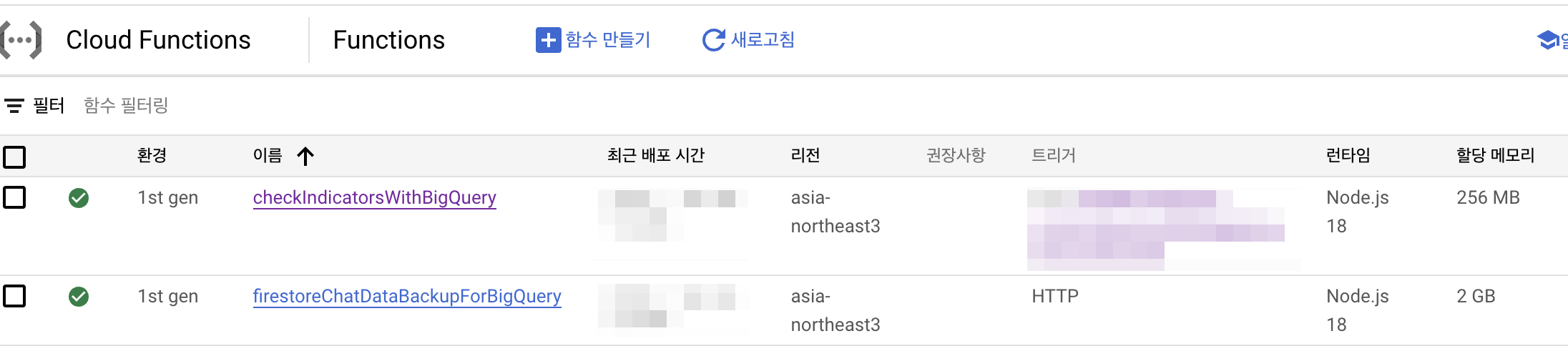
이렇게 구성하고, functions를 배포하면 위와 같이 Cloud Functions에 함수가 배포된 것을 확인할 수 있습니다. 함수를 클릭하여 실행하면 빅쿼리에 데이터가 적재되어 있을 겁니다.
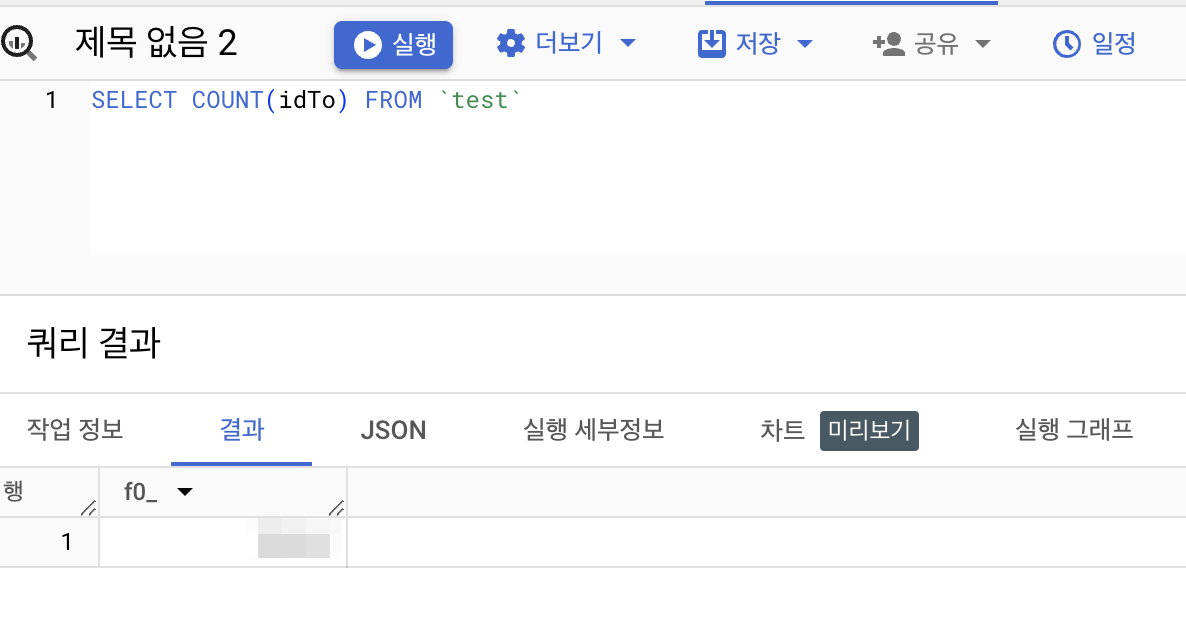
빅쿼리에 데이터가 잘 적재되었는지 확인하기 위해 BigQuery를 활용해서 데이터를 조회하면 원하는 결과를 얻을 수 있을 것입니다.

마치며
AWS 인프라만 다루다가, GCP 인프라를 다뤄야 하는 상황이 오면서, 여러 인프라를 다루며 성장할 수 있는 기회가 있다는 것에 감사함을 느끼고 있습니다. 좋은 기술을 배우는 것도 좋지만, 기술의 기반이 되는 기초적인 지식을 먼저 쌓는 것이 중요하다는 것을 다시금 깨달았습니다. 기초가 튼튼한 개발자가 되고 싶습니다.
출처
Firestore | Firebase
유연하고 확장 가능한 NoSQL 클라우드 데이터베이스를 사용해 클라이언트 측 개발 및 서버 측 개발에 사용되는 데이터를 저장하고 동기화하세요.
firebase.google.com
Cloud Firestore 데이터 모델 | Firebase
Google I/O 2023에서 Firebase의 주요 소식을 확인하세요. 자세히 알아보기 의견 보내기 Cloud Firestore 데이터 모델 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Clo
firebase.google.com
The Firebase Blog
News, tutorials, and updates from the Firebase team.
firebase.blog
Firestore로 실시간 채팅 앱 구현 (feat. React, Firebase)
이번 포스트에서는 React 채팅앱에 Firestore를 적용하는 방법을 공유드리고자 합니다. 기존에 polling 방식으로 채팅을 구현했을 때 속도도 너무 느리고, 싱크가 맞지 않아 실시간으로 데이터가 반영
velog.io
Cloud Firestore #1 NoSQL 데이터베이스란 무엇인가?
우선 저는 백엔드 전문가가 아님을 밝히고 글을 시작하겠습니다. 앱개발에 Cloud Firestore를 사용하기 위해 공부하는 중이며 공부한 내용을 정리도 할겸 글을 작성하게 되었습니다. 저와 마찬가지
flutter-chobo.tistory.com
Firebase Firestore에서 개인정보 보호하기
유저의 개인정보 보호는 소프트웨어 엔지니어링에서 아무리 강조해도 지나침이 없는 주제입니다. 이 글에서는 마이루틴이 Firestore에서 개인정보 보호를 위해 사용하고 있는 세 가지 방법을 소
blog.myroutine.team
Firestore를 BigQuery로 로드하여 SQL 쿼리문 사용하기
GCP에 존재하는 BigQuery를 이용하면, BigQuery에 로드된 Firestore의 데이터에 대해 SQL 쿼리를 쓸 수 있습니다.
blog.myroutine.team
구글 BigQuery 개요
본 문서는 Github Tutorial의 내용을 재구성한 것입니다! (20.05.20) 발표 자료로 만든 BigQuery의 모든 것(입문편)를 참고하셔도 좋을 것 같습니다! 약 270쪽 정도 됩니다 (2022년 10월 추가) 아래 내용보다
zzsza.github.io
'서버 개발' 카테고리의 다른 글
| 프로젝트 삽질기23 (feat Transactional) (0) | 2024.04.21 |
|---|---|
| 프로젝트 삽질기22 (feat 커넥션 풀 누수) (1) | 2024.02.18 |
| 프로젝트 삽질기20 (feat 검색 로그 구축 4) (0) | 2023.09.17 |
| 프로젝트 삽질기19 (feat 검색 로그 구축 3) (0) | 2023.09.17 |
| 프로젝트 삽질기18 (feat 검색 로그 구축 2) (0) | 2023.09.17 |



