
들어가며
사이드 프로젝트에서 푸시 알림을 활용한 서비스를 개발하고 있습니다. 그 과정에서 생각하고 배웠던 점들을 하나씩 작성하고자 합니다. DB를 공부하면서 소환사의 즐겨찾기를 조회하는 API가 어떤 성능을 지니고 있는지 알고 싶었습니다. 그래서 실행계획을 활용해서 쿼리를 분석해보니, 데이터가 많아지면 많아질수록 쿼리 시간이 증가하는 쿼리로 구성되어 있다는 것을 알 수 있었습니다. 이 글은 데이터가 많아도, 쿼리가 빠르게 될 수 있도록 설정하기 위해 삽질한 노력이 담겼습니다.

테스트 설계
먼저 쿼리 성능을 테스트하기 위해 다음과 같이 테이블을 생성했습니다.
CREATE TABLE "summoner_record" (
"id" BIGSERIAL NOT NULL,
"created_at" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT now(),
"updated_at" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT now(),
"deleted_at" TIMESTAMP, "name" character varying NOT NULL,
"tier" character varying,
"win" integer NOT NULL,
"lose" integer NOT NULL,
"profile_icon_id" integer NOT NULL,
"puuid" character varying NOT NULL,
"summoner_id" character varying NOT NULL,
"league_point" integer NOT NULL,
"rank" character varying,
CONSTRAINT "UQ_716eaabdfeca68d19b612ff783b" UNIQUE ("summoner_id"),
CONSTRAINT "PK_cb1476b13c099b057573ec4a7ef" PRIMARY KEY ("id")
);CREATE TABLE "user" (
"id" BIGSERIAL NOT NULL,
"created_at" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT now(),
"updated_at" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT now(),
"deleted_at" TIMESTAMP,
"user_id" character varying,
"password" character varying,
"device_id" character varying(50) NOT NULL,
"is_push" boolean NOT NULL DEFAULT false,
"firebase_token" character varying NOT NULL,
"current_hashed_refresh_token" character varying,
"logged_at" TIMESTAMP WITH TIME ZONE,
CONSTRAINT "UQ_758b8ce7c18b9d347461b30228d" UNIQUE ("user_id"),
CONSTRAINT "UQ_0232591a0b48e1eb92f3ec5d0d1" UNIQUE ("device_id"),
CONSTRAINT "PK_cace4a159ff9f2512dd42373760" PRIMARY KEY ("id")
);CREATE TABLE "favorite_summoner" (
"id" BIGSERIAL NOT NULL,
"created_at" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT now(),
"updated_at" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT now(),
"deleted_at" TIMESTAMP,
"user_id" bigint NOT NULL,
"summoner_id" character varying,
CONSTRAINT "PK_757ccf78852f33ca1149fff4ca7" PRIMARY KEY ("id")
);ALTER TABLE "favorite_summoner"
ADD CONSTRAINT "FK_cc85ee2ad134fcc7c77eced37c7"
FOREIGN KEY ("user_id") REFERENCES "user"("id")
ON DELETE CASCADE
ON UPDATE CASCADEALTER TABLE "favorite_summoner"
ADD CONSTRAINT "FK_01a5ec5c7c4f7121f4afe85ff23"
FOREIGN KEY ("summoner_id") REFERENCES "summoner_record"("summoner_id")
ON DELETE CASCADE
ON UPDATE CASCADE
위와 같이 테이블을 생성했다면, 그다음에는 테이블에 시드 데이터를 다음과 같이 넣었습니다. 먼저 summoner_record 테이블에 다음과 같이 시드 데이터를 넣었습니다.
DO $$
DECLARE i INTEGER := 1;
BEGIN WHILE i < 10
LOOP INSERT INTO summoner_record(name, tier, win, lose, profile_icon_id, puuid, summoner_id, league_point, rank)
VALUES(CONCAT('name', i), CONCAT('tier', i), i % 100, i % 100, i % 100, CONCAT('puuid', i), CONCAT('summonerId', i), i % 100, CONCAT('rank', i));
i := i + 1;
END LOOP;
END $$;
그 후 user 테이블에 다음과 같이 시드 데이터를 넣었습니다.
DO $$
DECLARE i INTEGER := 1;
BEGIN WHILE i < 2000
LOOP INSERT INTO "user"(user_id, password, device_id, is_push, firebase_token)
VALUES(CONCAT('userId', i), CONCAT('password', i), CONCAT('deviceId', i), true, CONCAT('firebaseToken', i));
i := i + 1;
END LOOP;
END $$;
마지막으로 favorite_summoner 테이블에 시드 데이터를 넣었습니다. 아래와 같이 진행한다면, 총 1만 개의 데이터가 들어갔을 것입니다.
DO $$
DECLARE i INTEGER := 1;
DECLARE j INTEGER := 1;
BEGIN WHILE i < 2000
LOOP
INSERT INTO "favorite_summoner"(user_id, summoner_id)
VALUES(i, CONCAT('summonerId', j));
INSERT INTO "favorite_summoner"(user_id, summoner_id)
VALUES(i, CONCAT('summonerId', j+1));
INSERT INTO "favorite_summoner"(user_id, summoner_id)
VALUES(i, CONCAT('summonerId', j+2));
INSERT INTO "favorite_summoner"(user_id, summoner_id)
VALUES(i, CONCAT('summonerId', j+3));
INSERT INTO "favorite_summoner"(user_id, summoner_id)
VALUES(i, CONCAT('summonerId', j+4));
i := i + 1;
j := j + 1;
END LOOP;
END $$;
쿼리 테스트
현재 서비스에서는 즐겨찾기를 최대 5명까지 할 수 있기에, 한 유저가 5명의 유저를 즐겨찾기 했다는 가정으로 데이터를 넣었습니다. 그럼 favorite_summoner 테이블에 총 10000개의 데이터가 존재할 것입니다. 이때 서비스에서는 다음과 같이 쿼리를 해야 했습니다.
SELECT "summonerRecord"."id"
AS "summonerRecord_id", "summonerRecord"."name"
AS "summonerRecord_name", "summonerRecord"."tier"
AS "summonerRecord_tier", "summonerRecord"."win"
AS "summonerRecord_win", "summonerRecord"."lose"
AS "summonerRecord_lose", "summonerRecord"."profile_icon_id"
AS "summonerRecord_profile_icon_id", "summonerRecord"."puuid"
AS "summonerRecord_puuid", "summonerRecord"."summoner_id"
AS "summonerRecord_summoner_id", "summonerRecord"."league_point"
AS "summonerRecord_league_point", "summonerRecord"."rank"
AS "summonerRecord_rank"
FROM "favorite_summoner" "favoriteSummoner"
INNER JOIN "summoner_record" "summonerRecord"
ON "summonerRecord"."summoner_id" = "favoriteSummoner"."summoner_id"
AND "summonerRecord"."deleted_at" IS NULL
WHERE ( "favoriteSummoner"."user_id" =4 )
AND ( "favoriteSummoner"."deleted_at" IS NULL )
그렇다면 쿼리의 실행 계획을 알기 위해 다음과 같이 쿼리를 작성했습니다.
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
SELECT "summonerRecord"."id"
AS "summonerRecord_id", "summonerRecord"."name"
AS "summonerRecord_name", "summonerRecord"."tier"
AS "summonerRecord_tier", "summonerRecord"."win"
AS "summonerRecord_win", "summonerRecord"."lose"
AS "summonerRecord_lose", "summonerRecord"."profile_icon_id"
AS "summonerRecord_profile_icon_id", "summonerRecord"."puuid"
AS "summonerRecord_puuid", "summonerRecord"."summoner_id"
AS "summonerRecord_summoner_id", "summonerRecord"."league_point"
AS "summonerRecord_league_point", "summonerRecord"."rank"
AS "summonerRecord_rank"
FROM "favorite_summoner" "favoriteSummoner"
INNER JOIN "summoner_record" "summonerRecord"
ON "summonerRecord"."summoner_id" = "favoriteSummoner"."summoner_id"
AND "summonerRecord"."deleted_at" IS NULL
WHERE ( "favoriteSummoner"."user_id" =4 )
AND ( "favoriteSummoner"."deleted_at" IS NULL )
그 결과 다음의 결과를 얻을 수 있었습니다.
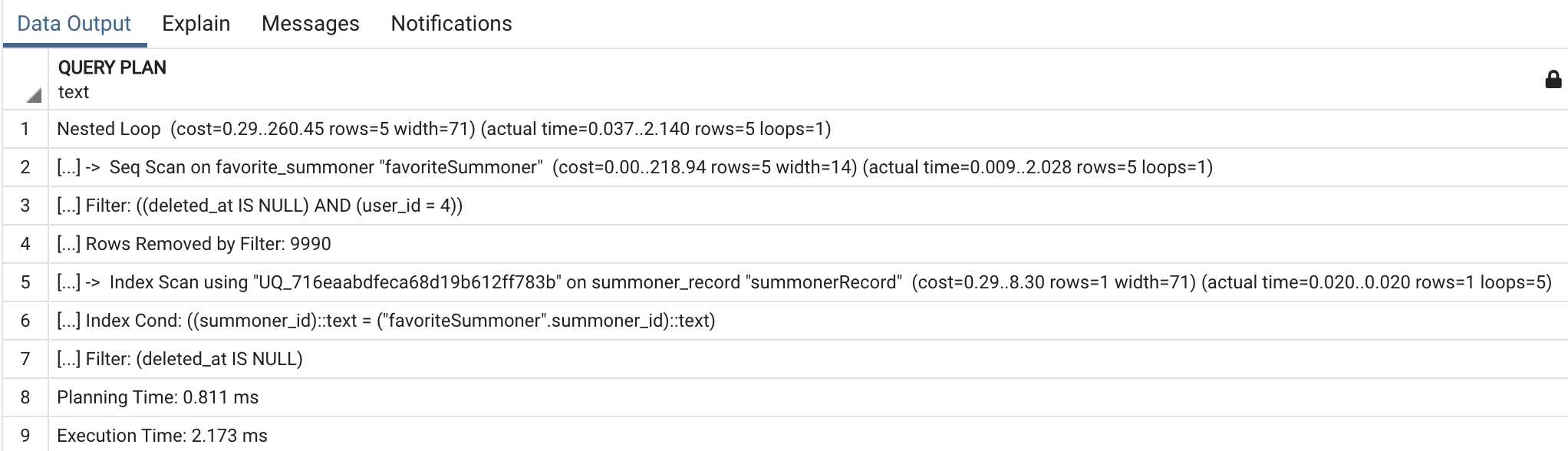

favorite_summoner 테이블에서 데이터를 찾을 때 Seq Scan을 해야 했고, summonerRecord에서는 Unique 설정이 되어있던 컬럼 값이 있었기에, 인덱스 설정이 적용됐습니다. 그럼 현재는 1만 건의 데이터로 테스트했다면, 만약 1000만 개의 데이터가 있다면 Seq Scan을 하는 부분에서, 어떤 결과를 얻을 수 있는지 확인해보고 싶었습니다.
이를 위해 데이터를 추가하고 다시 같은 쿼리를 실행했습니다.


그 결과 다음의 결과를 얻을 수 있었습니다. 데이터가 늘어나면 늘어날수록, 쿼리 시간이 증대되는 문제를 알 수 있었습니다. 이는 favorite_summoner 테이블에 인덱스 설정이 되어있지 않아서 생긴 문제였습니다. 그럼 여기서 INNER JOIN ON 부분에서, 인덱스 적용이 된다면 쿼리 결과가 어떻게 나올지 궁금했습니다. 이를 위해 favoriteSummoner의 summoner_id를 인덱스 설정해서 테스트를 진행했습니다.
CREATE INDEX "idx_favoriteSummoner_1" ON "favorite_summoner" ("summoner_id")
위와 같이 테이블에 인덱스를 추가하고, 쿼리 실행결과를 살펴봤습니다.


그 결과, 크게 달라진 점을 살펴볼 수 없었습니다. 그럼 WHERE 조건에서 user_id가 인덱스 되어 있지 않아서 생긴 문제라는 것을 알 수 있었습니다. 위에서 설정한 인덱스를 삭제하고, user_id만 인덱스를 설정해봐야겠다고 생각했습니다.
DROP INDEX "public"."idx_favoriteSummoner_1"
CREATE INDEX "idx_favoriteSummoner_1" ON "favorite_summoner" ("user_id")
위와 같이 인덱스를 설정하고, 같은 쿼리를 실힝해보면 다음과 같은 결과를 얻을 수 있었습니다.


DB 메모리 영역에서 user_id가 2004인 부분만을 가져오면 되는 것이기에, 쿼리 시간이 획기적으로 줄어든 것을 살펴볼 수 있었습니다.
여기서 더 나아가서, favorite_summoner 테이블에서 summoner_id가 외래 키 설정이 되어있기 때문에, favorite_summoner 테이블의 summoner_id를 함께 복합 인덱스로 설정하면, summoner_record 테이블의 쿼리를 하지 않아도 되게끔 설정해서, 테이블 쿼리 속도를 더 줄일 수 있지 않을까 생각했습니다. 이를 위해 index를 변경했습니다. 테스트를 위해 인덱스를 변경했습니다.
DROP INDEX "public"."idx_favoriteSummoner_1"
CREATE INDEX "idx_favoriteSummoner_1" ON "favorite_summoner" ("user_id", "summoner_id");
WHERE 조건에서 user_id를 먼저 찾아야 하는 관계로, user_id를 인덱스의 첫 번째로 추가했고, INNER JOIN ~ ON 부분에서 조인 컬럼인 summoner_id를 찾아야 하기에, 복합 인덱스에 summoner_id를 추가했습니다. 인덱스를 추가하고 데이터를 살펴보면 다음과 같은 결과를 볼 수 있습니다.


조인 컬럼을 찾지 않아도 됨으로, 시간을 더 단축시킬 수 있었고, 그 결과 1000만 건 데이터를 조회할 때 최종적으로 0.023ms 초가 걸린다는 것을 알 수 있었습니다. 처음에 657ms초가 걸리던 것에서 0.023초가 걸리는 것으로, 약 3만 배의 성능 향상을 할 수 있었습니다. 그럼 여기서 궁금했던 것은 만약 summoner_id를 user_id보다 먼저 인덱스를 설정한 경우에는 조인 컬럼과 조회 컬럼 중 어떤 것을 먼저 우선적으로 데이터를 찾는 것인지 궁금했습니다. 이는 다음과 같은 결과를 얻을 수 있습니다.

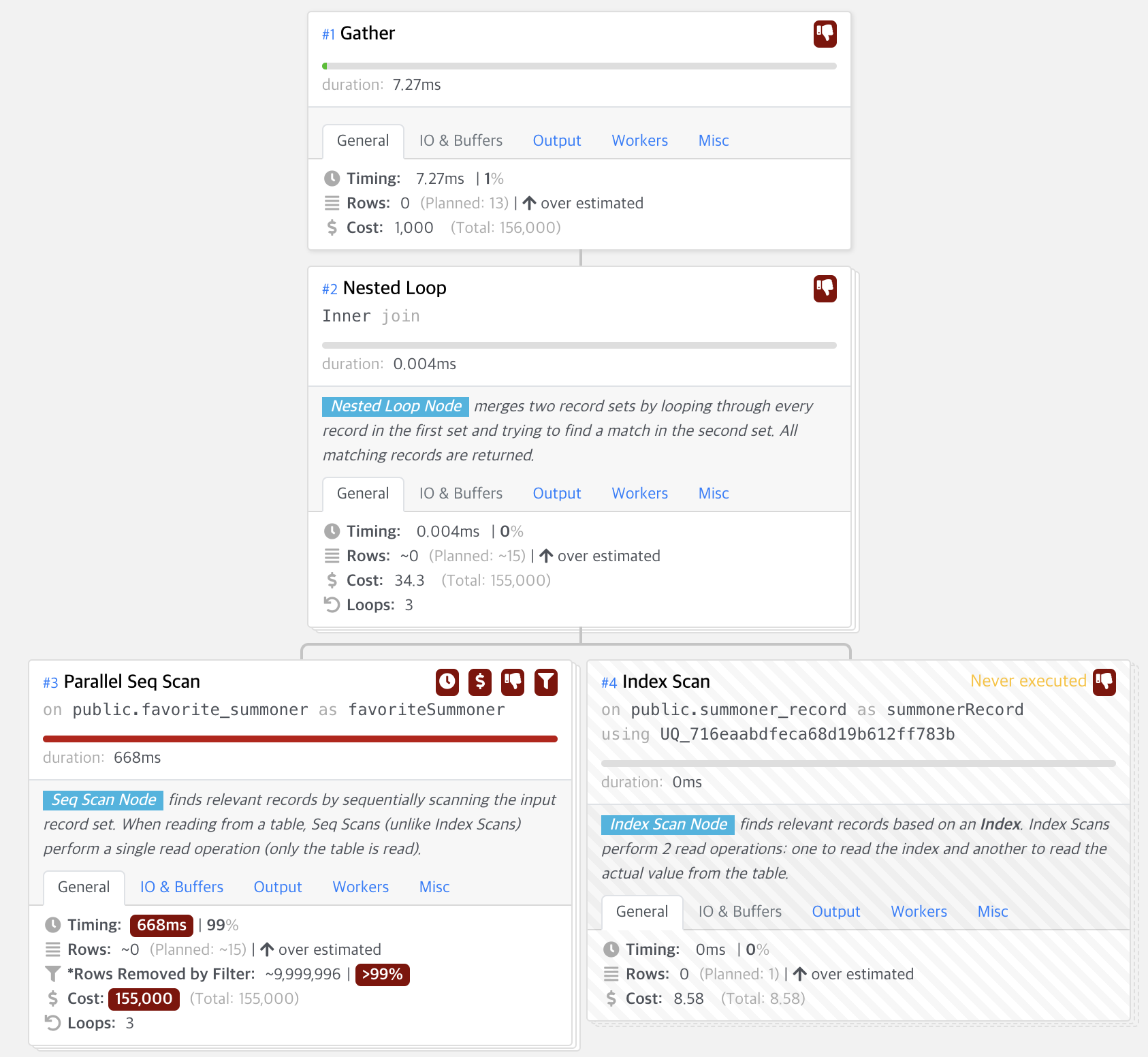
위의 결과를 통해, 조인 컬럼을 WHERE 조건 컬럼보다 먼저 인덱스 설정을 하는 경우, 인덱싱이 제대로 되지 않는다는 것을 알 수 있었습니다. 위와 같은 쿼리 튜닝을 통해 인덱스에 대해 더 잘 이해할 수 있었습니다.

마치며
앞으로도 팀의 발전을 돕는 개발자가 되기 위해 노력하려 합니다. 팀에 필요한 부분이 무엇일지 고민하면서, 팀에 도움이 된다면, 열심히 공부해서 실무에 적용할 수 있는 개발자가 되기 위해 노력하고 싶습니다. 팀의 성장에 기여할 수 있는 개발자가 되겠습니다.
참고 및 출처
1. 커버링 인덱스 (기본 지식 / WHERE / GROUP BY)
일반적으로 인덱스를 설계한다고하면 WHERE 절에 대한 인덱스 설계를 이야기하지만 사실 WHERE 뿐만 아니라 쿼리 전체에 대해 인덱스 설계가 필요합니다. 인덱스의 전반적인 내용은 이전 포스팅을
jojoldu.tistory.com
2. 커버링 인덱스 (WHERE + ORDER BY / GROUP BY + ORDER BY )
지난 시간에 이어 이번엔 ORDER BY에 대해 알아보겠습니다. 2-1. WHERE + ORDER BY 일반적으로 ORDER BY 의 인덱스 사용 방식은 GROUP BY와 유사합니다만, 한가지 차이점이 있습니다. 바로 정렬 기준입니다. My
jojoldu.tistory.com
커버링 인덱스
조회 성능 개선 미션을 진행하며 를 알게 됐다. 처음 보는 단어여서 이게 어떤 인덱스일까 궁금했고, 바로 찾아보고 이해했다. 그러면서 한번 내용을 글로 정리하면 좋을 것 같다는 생각을 했다.
tecoble.techcourse.co.kr
PostgreSQL의 슬로우 쿼리에 대처하기
데이터베이스에 적절한 인덱스를 추가하여 슬로우 쿼리를 빠르게 만들고 리소스 사용을 줄인 사례를 공유합니다.
hyperconnect.github.io
여러컬럼으로 Join 맺어야할 경우의 인덱스
실제 발생했던 쿼리) SELECT i.id, i.titles[1] title, i.icon_url, ic.user_id FROM institutions i INNER JOIN interested_corporations ic ON ic.institution_id = i.id AND ic.deleted_at IS NULL INNER JOIN..
jojoldu.tistory.com
'서버 개발' 카테고리의 다른 글
| 프로젝트 삽질기6 (feat 정적 팩토리 메서드) (2) | 2022.07.09 |
|---|---|
| 프로젝트 삽질기5 (feat Swagger 보안 구성) (0) | 2022.06.03 |
| 프로젝트 삽질기4 (feat Sentry Slack 연동) (0) | 2022.04.29 |
| 프로젝트 삽질기3 (feat Enum) (0) | 2022.04.22 |
| 프로젝트 삽질기1 (feat Table Scan 실행계획) (0) | 2022.04.09 |



