
들어가며
사이드 프로젝트에서 푸시 알림을 활용한 서비스를 개발하고 있습니다. 그 과정에서 설정한 Index가 제대로 동작하는지 알기 위해, 그리고 효과적으로 커버링 인덱스를 적용하기 위해 쿼리의 실행계획을 분석했습니다. 그 과정에서, 설정한 Index가 제대로 동작하지 않고, 실행계획에서 Seq Scan으로 동작하고 있다는 것을 알았습니다. 여기서 Seq Scan은 무엇이며, PostgreSQL에서 테이블 스캔은 어떤 종류가 있는지 알아야겠다고 생각했습니다. 이 글은 [PG] 쿼리 실행 계획 분석하기 - Table Scan을 참고했으며, 실행계획에 대해 공부한 내용을 작성했습니다.

실행 계획
Index가 제대로 동작하는지 알기 위해 다음과 같은 쿼리의 실행 계획을 살펴봤습니다.
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
SELECT *
FROM "favorite_summoner" "favoriteSummoner"
INNER JOIN "summoner_record" "summonerRecord"
ON "summonerRecord"."summoner_id" = "favoriteSummoner"."summoner_id"
AND "summonerRecord"."deleted_at" IS NULL
WHERE "favoriteSummoner"."user_id" =2
AND "favoriteSummoner"."deleted_at" IS NULL
그 결과 다음과 같은 결과를 얻을 수 있었습니다.
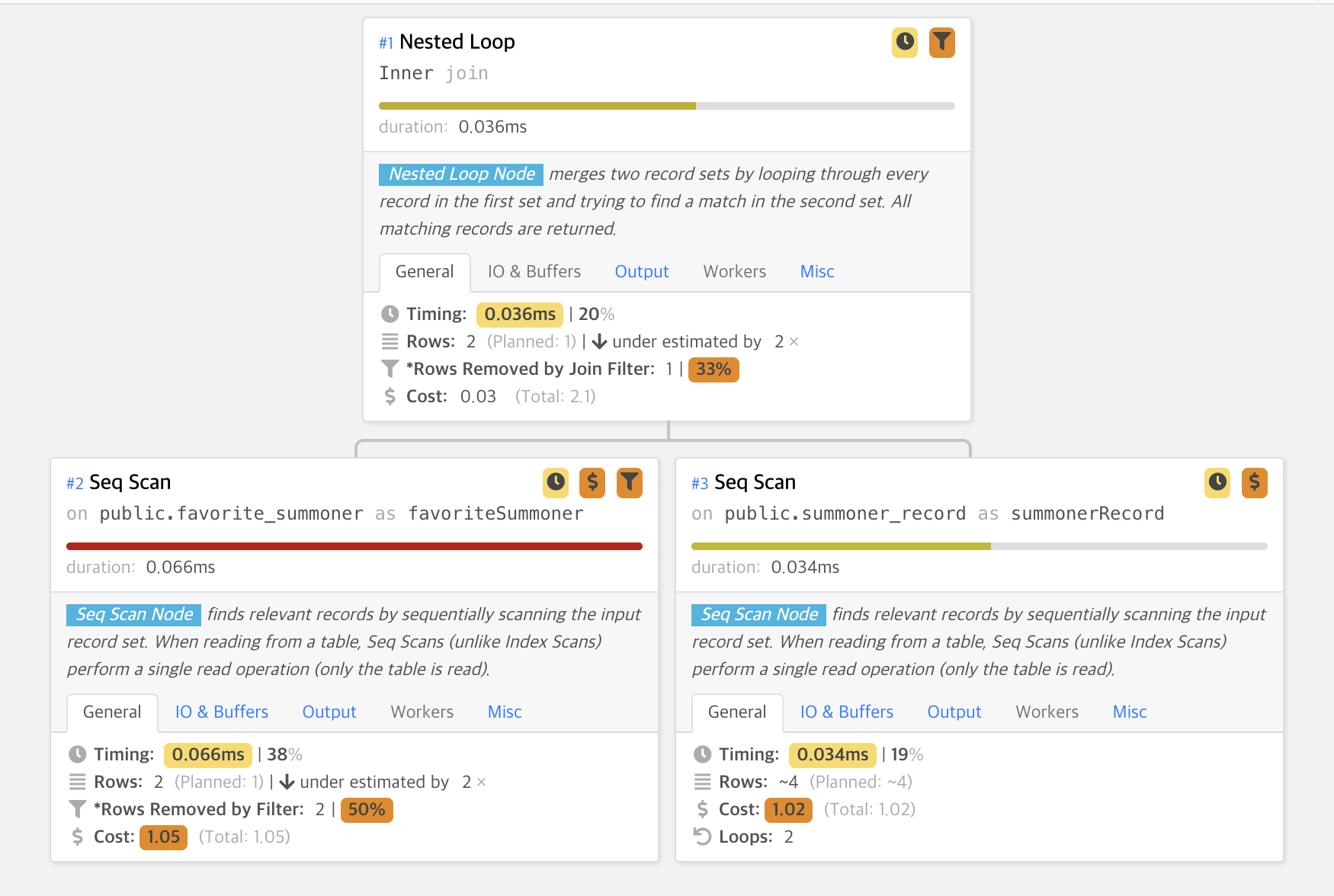
여기서 Index Scan을 활용한 것이 아닌, Seq Scan을 활용해서 쿼리 했다는 것을 알 수 있었습니다. 처음 실행 계획을 분석하면서, PostgreSQL의 Table Scan 방식은 어떻게 이루어지는지 궁금했습니다.
Table Scan
PostgreSQL은 다음 5가지 스캔 방식을 사용합니다.
- Sequential Scan
- Index Scan
- Index Only Scan
- Bitmap Scan
- TID Scan
그럼 다음 5가지 스캔 방식에 대해 알아보기 전에, 테스트할 테이블을 설정하겠습니다.
CREATE TABLE post (
id serial PRIMARY KEY,
title varchar(255),
author varchar(255),
created_at timestamp
);
테스트할 테이블은 위와 같은 쿼리로 생성했습니다. 게시판의 게시물에 해당하는 테이블이며, 사용자 테이블은 생성하지 않은 관계로 외래 키 참조는 생략했습니다.
DO $$
DECLARE
i INTEGER := 1;
BEGIN
WHILE i < 1000000 LOOP
INSERT INTO post(title, author, created_at)
VALUES(CONCAT('title', i), CONCAT('author', i % 100), now() + i * INTERVAL '1 second');
i := i + 1;
END LOOP;
END $$;
데이터는 위와 같은 쿼리로 생성했다. 'title{i}'라는 서로 다른 제목을 갖는 100만 개의 게시물이 생성되고, 사용자는 총 100명으로 'author{0-100}'의 이름을 갖습니다. 100명의 사용자가 10,000개씩 게시물을 작성한 상황입니다. 생성 날짜는 모두 다르게 설정했습니다.
1. Sequential Scan
먼저 Sequential Scan은 테이블의 모든 데이터를 하나씩 확인하는 방법입니다. 주로 인덱스가 없는 column을 조건으로 검색할 경우에 사용됩니다.
EXPLAIN ANALYZE
SELECT * FROM post WHERE title = 'title5432';
그럼 위의 쿼리를 활용해서 쿼리 실행 계획을 살펴보겠습니다.

위 쿼리는 다음과 같이 2단계의 실행 계획으로 이루어졌습니다.
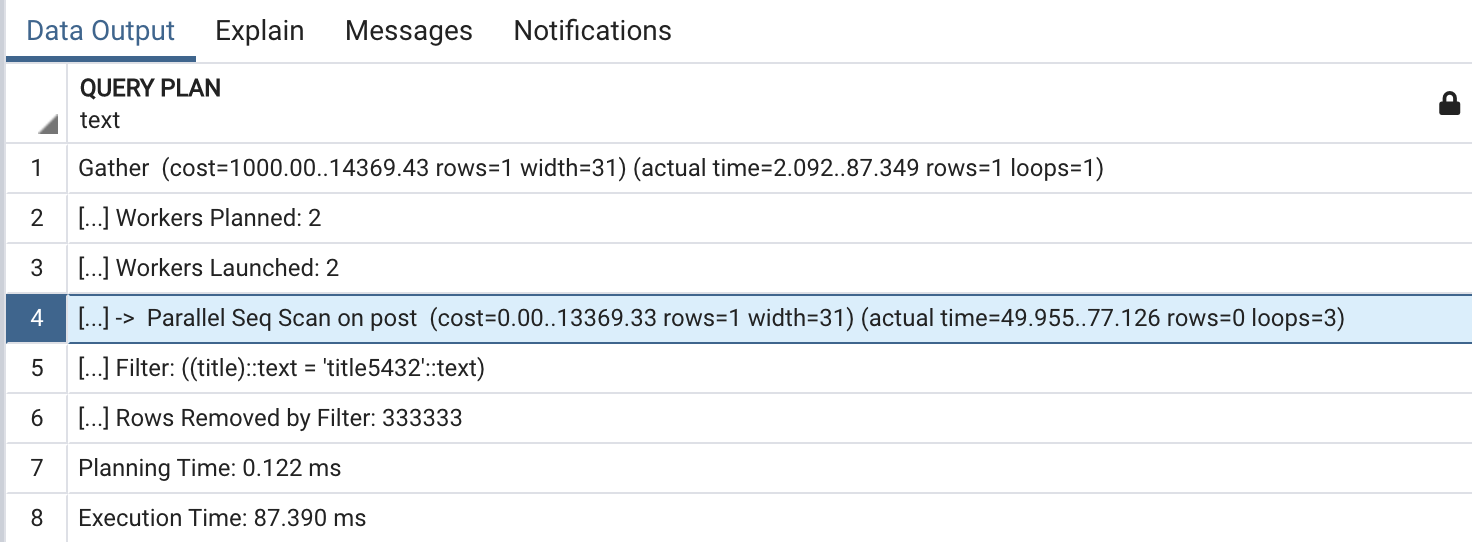
각 단계는 4번째 줄의 Seq Scan과 1번째 줄의 Gather입니다. 화살표로 인덴트된 실행 계획은 child plan으로, 해당 단계에서 실행된 결과를 상위 단계에서 처리한다는 뜻으로, 안쪽 인덴트에서 바깥으로 실행계획의 흐름을 따라가야 합니다.
title은 인덱스가 없는 column이기 때문에 테이블의 모든 데이터를 조회하는 방법밖에 없습니다. 위 결과를 보자면 PostgreSQL은 2개의 워커 프로세스를 생성해 병렬적으로 테이블을 순차 스캔했으며, 각 워커 프로세스가 찾아낸 row를 종합해서 쿼리를 수행했음을 알 수 있습니다. (Parallel Seq Scan)
실행 계획에서 또 다른 중요한 키워드는 Rows Removed by Filter입니다. 이 결과는 테이블의 row를 조회했으나, 우리가 찾는(id = 5432) row가 아니어서 버려진 row의 수를 나타냅니다. 이 수가 적을수록 최적화된 쿼리라고 할 수 있습니다.
3번의 루프(loop=3)를 돌면서 333,333개의 row를 버렸으니 1개의 row를 찾기 위해 100만 개의 row를 모두 다 조회했다는 뜻입니다.
마지막 줄에서는 실제 실행에 소요된 시간을 확인할 수 있습니다.
2. Index Scan
Index Scan은 말그대로 인덱스를 탐색하는 방식을 말합니다. 인덱스가 만들어진 column을 조건문으로 조회할 때 데이터베이스가 선택하는 방식입니다.
EXPLAIN ANALYZE
SELECT * FROM post WHERE id = 5432;
id column은 PK로 지정했기 때문에 테이블을 생성할 때 인덱스가 자동으로 생성되고 정렬됩니다. 그렇기 때문에 id로 조회할 때 Index Scan을 이용해서 필요한 row만 가져올 수 있습니다. 그렇기 때문에 실행시간도 스캔 방법 중에 가장 빠릅니다.
EXPLAIN ANALYZE
SELECT * FROM post WHERE id < 5432;

범위 조회에서도 Index Scan을 사용하는 것을 확인할 수 있습니다.
EXPLAIN ANALYZE
SELECT * FROM post WHERE id < 5432 ORDER BY id DESC;
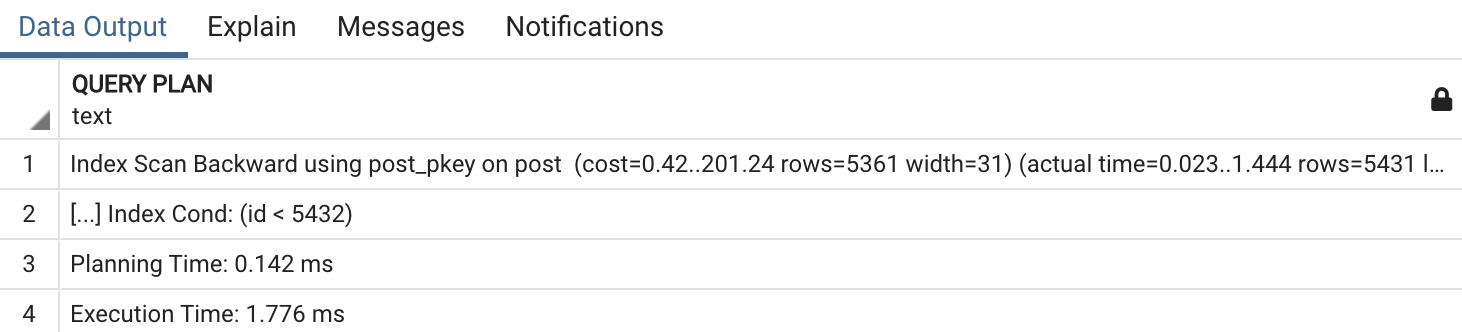
인덱스는 항상 정렬되어있기 때문에 역순으로 조회가 가능합니다. 따라서 Index Scan Backward 방식을 이용해서 id를 역순으로 조회하여 쿼리를 효율적으로 처리하는 것을 확인할 수 있습니다.
재밌는 것은 인덱스가 있는 column에서도 Sequential Scan 방식이 사용될 수 있다는 것입니다.
EXPLAIN ANALYZE
SELECT id FROM post WHERE id > 5432;
100만 개의 row 중에 5433개의 row를 제외한 99만 4567개의 row를 가져오는 쿼리입니다. 데이터베이스 엔진이 이 수를 계산해서 인덱스를 조회하고 데이터에 접근하는 것보다 바로 데이터를 조회하는 것이 더 낫다고 판단하고, Index Scan 대신 Sequential Scan을 사용했습니다. 이처럼 데이터베이스 엔진은 인덱스가 있다고 Index Scan을 사용하는 것이 아니라, 해당 쿼리에 적합하다고 판단되는 방식을 이용하는 것을 확인할 수 있습니다.
3. Index Only Scan
Index Only Scan은 인덱스에 필요한 데이터가 있는 경우 사용되는 방식입니다. 인덱스에 필요한 값이 있기 때문에, 실제 데이터를 fetch하지 않아도 됩니다. 필요한 값이 인덱스에 모두 있는 것을 커버링 인덱스라고 하고, 커버링 인덱스를 이용하는 스캔을 Index Only Scan이라고 합니다.
EXPLAIN ANALYZE
SELECT id FROM post WHERE id = 5432;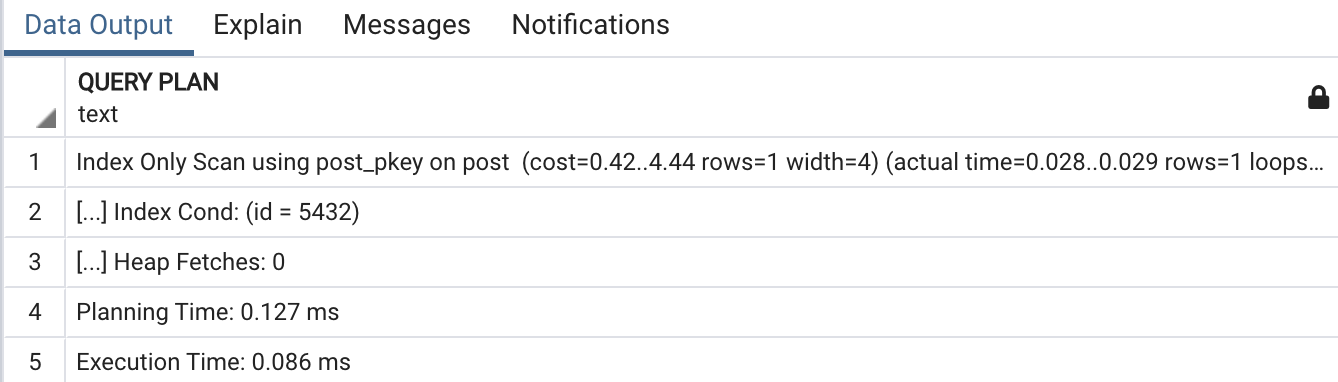
위 쿼리처럼 필요한 컬럼 값이 인덱스에 이미 존재할 때 사용됩니다.
4. Bitmap Scan
Bitmap Scan은 Index Scan과 Sequential Scan이 조합된 방식입니다. 데이터베이스가 Bitmap Scan을 이용하도록 author 칼럼을 인덱스로 생성한 후 author로 검색을 해봤습니다.
CREATE INDEX idx_author ON post(author);
EXPLAIN ANALYZE
SELECT id FROM post WHERE id < 600000 AND author = 'author54';
데이터베이스에서 첫 번째로 Bitmap Index Scan이 일어나고, 두 번째로 Bitmap Heap Scan이 일어난 것을 확인할 수 있습니다. Bitmap Index Scan 단계에서 인덱스 자료구조를 스캔하며 조건에 해당하는 인덱스의 데이터를 이용해서 bitmap을 생성합니다. 이 bitmap에는 인덱스에 해당하는 테이블의 row에 접근할 수 있는 정보가 담겨 있습니다. Bitmap Heap Scan 단계에서는 앞서 생성된 bitmap을 스캔하면서 조건에 맞는 실제 데이터를 가져오게 됩니다.
위 예시에서는 author 인덱스를 이용해서 author가 'author54'인 10,000개의 데이터에 접근할 수 있는 bitmap을 생성하고, id가 600,000 이하인 6,000개의 row를 결과로 가져왔습니다. 여기서도 재밌는 것은 가져와야 할 데이터가 줄어들면(이 상황에서는 id의 범위 조건이 줄어들면) 데이터베이스가 Index Scan을 사용한다는 것입니다.
EXPLAIN ANALYZE
SELECT id FROM post WHERE id < 200000 AND author = 'author54';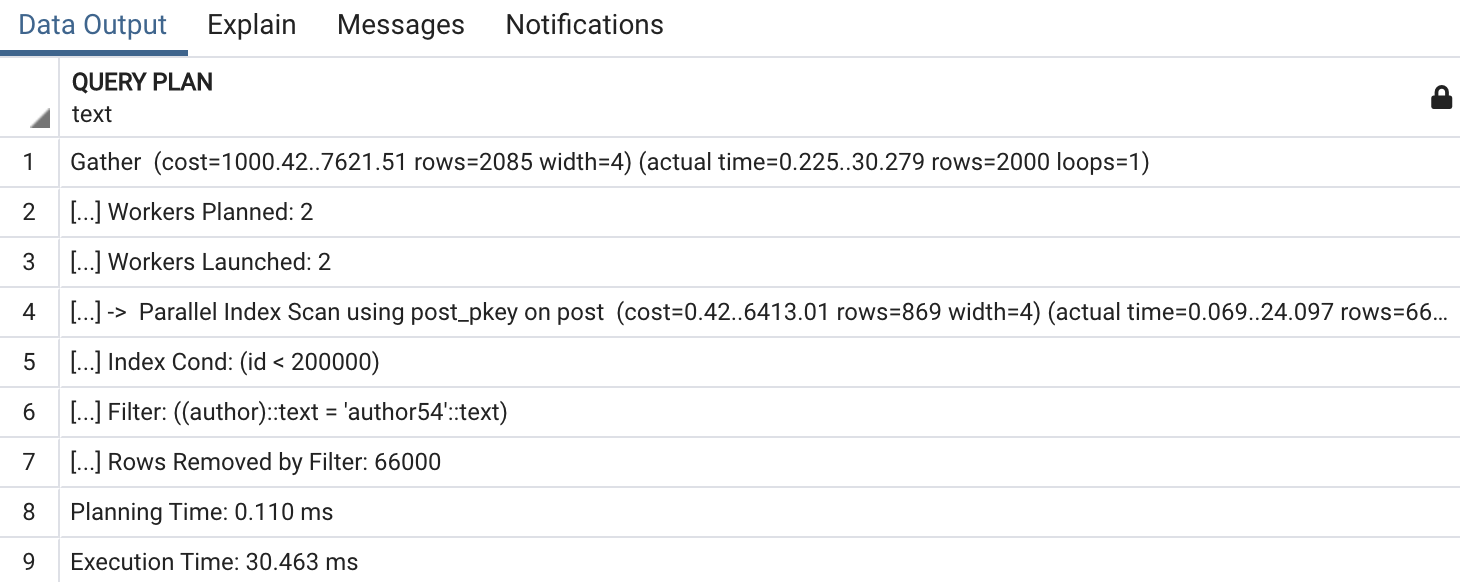
id 조건 범위를 200,000으로 줄였더니 데이터베이스가 Parallel Index Scan을 사용합니다. 데이터베이스가 조건문에 사용할 column의 인덱스 유무뿐만 아니라 실제로 가져와야 할 데이터의 크기도 고려해서 Table Scan 방법을 정한다는 것을 확인할 수 있습니다.
5. TID Scan
TID Scan은 데이터베이스가 실제 테이블의 데이터를 식별하기 위해 사용하는 TID라는 것을 이용한 쿼리를 사용할 때 사용됩니다.
EXPLAIN ANALYZE
SELECT id FROM post WHERE ctid = '(1, 1)';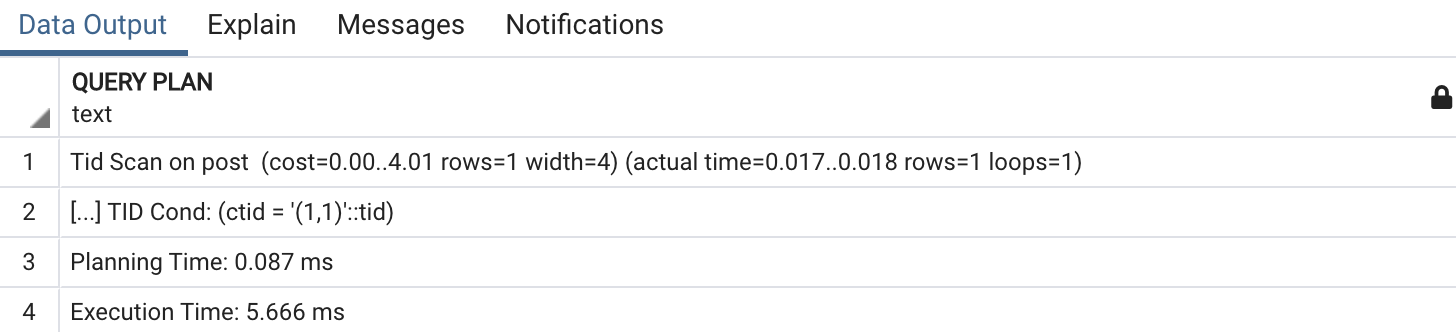
이 TID는 Tuple Indecator의 줄임말로, 특정 row의 실제 위치를 나타내는 6byte 값으로, 4byte는 페이지 번호, 2byte는 페이지 내의 튜플 인덱스를 나타낸다고 합니다. (PostgreSQL 버전의 rowid 개념으로 보임)
Table Scan 프로젝트 적용하기
실행 계획을 보면서, 다시 쿼리를 분석해봤습니다. 그 결과 왜 프로젝트에서 Index Scan 대신 Sequential Scan을 사용했는지 알 수 있었습니다.
EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
SELECT *
FROM "favorite_summoner" "favoriteSummoner"
INNER JOIN "summoner_record" "summonerRecord"
ON "summonerRecord"."summoner_id" = "favoriteSummoner"."summoner_id"
AND "summonerRecord"."deleted_at" IS NULL
WHERE "favoriteSummoner"."user_id" =2
AND "favoriteSummoner"."deleted_at" IS NULL
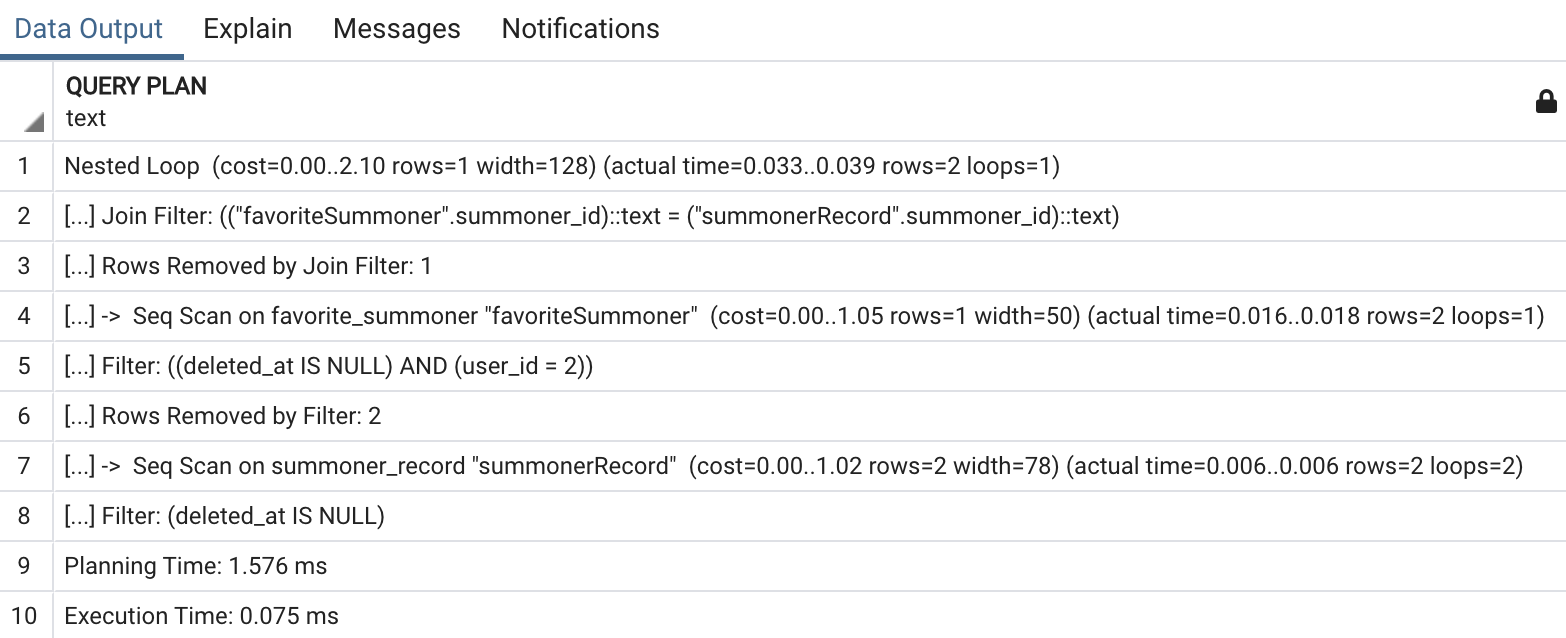
위의 테이블에 데이터가 많이 않은 상황에서, 데이터베이스 엔진이 이 수를 계산해서 인덱스를 조회하고 데이터에 접근하는 것보다 바로 데이터를 조회하는 것이 더 낫다고 판단하고, Index Scan 대신 Sequential Scan을 사용했을 것입니다.
SET enable_seqscan = OFF;
EXPLAIN ANALYZE
SELECT *
FROM "favorite_summoner" "favoriteSummoner"
INNER JOIN "summoner_record" "summonerRecord"
ON "summonerRecord"."summoner_id" = "favoriteSummoner"."summoner_id"
AND "summonerRecord"."deleted_at" IS NULL
WHERE "favoriteSummoner"."user_id" =2
AND "favoriteSummoner"."deleted_at" IS NULL
만약 SET enable_seqscan = OFF를 추가하고 실행하면 다음과 같은 결과를 얻을 수 있습니다.

즉 DB의 데이터 건수에 따라 optimizer가 Index Scan을 할지, Sequential Scan을 할지 선택하게 됩니다. Seq Scan이 나왔을 때 당황했던 경험이 좋은 가르침을 준 것 같습니다. 항상 쿼리를 구성할 때, 실행계획을 분석해보면서 효율적인 쿼리 방식인지 늘 고민하는 연습을 해야겠다고 생각했습니다.

마치며
앞으로도 팀의 발전을 돕는 개발자가 되기 위해 노력하려 합니다. 팀에 필요한 부분이 무엇일지 고민하면서, 팀에 도움이 된다면, 열심히 공부해서 실무에 적용할 수 있는 개발자가 되기 위해 노력하고 싶습니다. 팀의 성장에 기여할 수 있는 개발자가 되겠습니다.
참고 및 출처
postgres에서 index가 생성되어 있는데, index scan이 아니라 seq scan을 하는지 궁금합니다.
일단 문제를 알게된 배경은 select를 할때 분명히 해당 select 문을 고려하여 인덱스를 생성해 놓았고, 개발 db(로컬 db)에서는 index scan이 의도대로 잘 이루어져 방심하고있다가. production db에서는 seq
hashcode.tistory.com
[PG] 쿼리 실행 계획 분석하기 - Table Scan
데이터베이스에 날릴 쿼리를 최적화하기 위해서는, 데이터베이스가 실제로 쿼리를 실행하는 방식과 해당 쿼리의 성능을 알고 있어야 한다. 그러기 위해서 데이터베이스의 쿼리 실행 계획(Query
seungtaek-overflow.tistory.com
'서버 개발' 카테고리의 다른 글
| 프로젝트 삽질기6 (feat 정적 팩토리 메서드) (2) | 2022.07.09 |
|---|---|
| 프로젝트 삽질기5 (feat Swagger 보안 구성) (0) | 2022.06.03 |
| 프로젝트 삽질기4 (feat Sentry Slack 연동) (0) | 2022.04.29 |
| 프로젝트 삽질기3 (feat Enum) (0) | 2022.04.22 |
| 프로젝트 삽질기2 (feat 쿼리 튜닝, 인덱스) (0) | 2022.04.11 |



